О журнале
Рекомендации
Интеллектуальная система тематического исследования научно-технической информации (ИСТИНА)
В.А. Васенин, С.А. Афонин, Д.Д. Голомазов, А.С. Козицын
_______________________
В.А. Васенин, С.А. Афонин, Д.Д. Голомазов, А.С. Козицын
Аннотация
Настоящая работа посвящена описанию Интеллектуальной Системы Тематического Исследования НАучно-технической информации. Задача системы − сбор, учет, систематизация, хранение, анализ и выдача по запросу информации, характеризующей результаты деятельности научных и образовательных организаций. Представлено описание функциональных возможностей системы, включая автоматизированный ввод данных, отображение их в открытом доступе, автоматическое формирование отчетных материалов, статистический и тематический анализ. Рассмотрены вопросы использования онтологий для учета специфики различных факультетов. Приведена краткая характеристика результатов внедрения системы в МГУ им. М.В. Ломоносова с привлечением более 6800 сотрудников из 750 подразделений.
Ключевые слова: научная информация, анализ информации, публикация, неструктурированные данные, автоматический сбор информации, библиографические ссылки, отображение данных в открытом доступе, Web of Science, информация о публикациях, число цитирования статей
Система ИСТИНА предназначена для управления научной информацией. Под научной информацией понимаются данные, характеризующие результаты деятельности научных организаций, в том числе сведения о публикациях, патентах, научных отчетах, докладах на конференциях, об участии в редколлегиях журналов, программных комитетах конференций, членстве в диссертационных советах, о руководстве диссертациями, авторстве учебных курсов и других видах научной, преподавательской и научно-организационной деятельности. Управление такой информацией включает ее сбор, учет и систематизацию, хранение, анализ (статистический и семантический) и выдачу по запросу.
Систему можно использовать для контроля и анализа научной деятельности сотрудников как одной организации, так и большого числа организаций, например, в отдельном регионе или в стране в целом. Научным сотрудникам система предоставляет возможность вести учет результатов своей научной деятельности и в автоматизированном режиме формировать различные научные отчеты. Руководителям различного уровня система позволяет проводить автоматизированный количественный и тематический анализ научной деятельности каждого сотрудника, отдельных подразделений, всего учреждения и в перспективе групп организаций регионального и национального масштаба.
Основные функции системы можно разделить на четыре категории: ввод данных; отображение данных в открытом доступе; формирование отчетов и представление данных для сотрудников в различных форматах; анализ статистических показателей по подразделениям и по тематике.
Ввод данных
Во многих крупных библиографических системах используются средства автоматического сбора информации о результатах научной деятельности ученых. В качестве источников информации обычно выступают либо базы данных издательств, с которыми были заключены соглашения о сотрудничестве, либо веб-сайты в интернете. С одной стороны, этот подход позволяет автоматически (без участия самих авторов) обработать большие объемы данных и построить систему, охватывающую значительное число публикаций. С другой стороны, подобная автоматизация неизбежно приводит к существенным ограничениям точности и полноты извлекаемой информации. Под полнотой будем понимать:
• количество ученых, результаты (показатели) деятельности которых введены в систему;
• количество типов результатов деятельности, обрабатываемых системой (например, публикации, патенты, отчеты, доклады на конференциях);
• количество результатов по каждому из типов деятельности отдельного ученого.
Под точностью имеются в виду следующие характеристики системы:
• корректность данных о результатах деятельности ученых (правильность названий публикаций, номеров страниц и других данных);
• корректность разрешения неоднозначностей имен авторов работ (публикаций, патентов, диссертаций и др.).
Анализ информации из нескольких наиболее крупных и широко используемых программных систем – Thomson Reuters, Web of Knowledge, Scopus, Google Scholar, российских eLibrary.ru и MathNet.ru − позволяет сделать следующие выводы.
В случае, когда информация извлекается из данных издательств-партнеров, ее полнота ограничена фиксированным перечнем их изданий. Например, даже в самых крупных комплексах, таких как Web of Knowledge и Scopus, целые категории источников, в частности, российские журналы, представлены крайне слабо. В таких системах учитывается большое число работ многих ученых, но при условии, что они попадают под заданные критерии, в частности, напечатаны в определенных журналах в течение некоторого промежутка времени (например, в eLibrary.ru учитываются статьи начиная с 1970 г.). Отметим, что эти недостатки во многом преодолены в системе Google Scholar, в которую данные поступают из открытых источников интернета. Однако и в ней обрабатывается информация только о публикациях и патентах.
Загрузка и проверка крупных объемов данных требует трудоемкой работы экспертов либо интеллектуальных автоматических алгоритмов. Применение последних неизбежно снижает точность информации. Если данные поступают в структурированном виде, например, от издательств, то они обладают высоким уровнем корректности. При загрузке неструктурированных данных из интернета их корректность ниже. При этом в обоих случаях второй показатель точности, а именно корректность разрешения неоднозначностей имен авторов, удержать в нужном диапазоне особенно сложно. Так, в существующих системах часто встречается ситуация, когда одному автору с распространенной фамилией (например, Ли, Смит или Иванов) оказываются приписаны десятки тысяч публикаций, на самом деле принадлежащих десяткам или даже сотням разных авторов.
Для повышения точности и полноты информации в системе ИСТИНА выбран подход, отличающийся от описанных выше. Он основан на следующих соображениях.
Предполагается, что автор работы (публикации, патента и т.п.) наиболее точно знает ее выходные данные, а также тех, кто перечислен среди соавторов работы. Информация о соавторах является наиболее ценной, так как позволяет сопоставить авторов добавляемой работы с конкретными объектами в базе данных системы. Процесс сопоставления, в частности, включает выбор нужного объекта, соответствующего автору, из множества однофамильцев в базе данных. Для эффективного автоматизированного выполнения подобной привязки используется следующий алгоритм.
При добавлении работы, например публикации, в систему поступает список имен ее авторов в виде текстовой строки. Необходимо разбить эту строку на части и сопоставить с ними объекты (персоналии) из базы данных. Для этого выполняется поиск похожих объектов (ученых) в базе данных системы, в процессе которого вычисляются несколько функций похожести, разделенные на два класса: функции сильной и слабой похожести. К функциям сильной похожести относятся проверки совпадения: полного имени; фамилии и инициалов; полного имени после добавления или опускания слов (например, «Иванов Иван Иванович» и «Иванов Иван»); фамилии и инициалов после добавления и опускания инициалов (например, «Петров А.» и «Петров А.В.»). Функции слабой похожести основаны на алгоритме вычисления расстояния Левенштейна [1] и расширении алгоритма Рэтклиффа–Обершелпа [2] для сравнения двух последовательностей элементов. Каждому кандидату, то есть ученому из базы данных системы, присваивается определенный вес от 0 до 1, который равен максимальному значению функций похожести между ним и именем автора работы. После отбора и оценки всех кандидатов для каждого автора выбирается одно из трех возможных решений системы.
Во-первых, если для автора не найдено кандидатов с оценкой, превышающей пороговое значение, то система предлагает пользователю добавить в базу данных нового ученого (это можно сделать прямо в процессе добавления публикации, выбрав соответствующую опцию).
Во-вторых, если наибольшее значение функции похожести было достигнуто только относительно одного кандидата, то система отображает всех кандидатов и выбирает по умолчанию наиболее подходящего из них. Наконец, если нескольким кандидатам присвоено одинаковое (и наибольшее) значение функции похожести, то система отображает всех кандидатов и не делает выбора по умолчанию, предлагая пользователю выбрать нужного сотрудника самому.
Отметим, что у каждого пользователя есть возможность заранее добавить в свой профиль список своих «альтернативных имен», то есть других вариантов написания своего полного или краткого имени, которые используются в выходных данных его работ. Например, можно указать свою девичью фамилию, полное или краткое имя на английском или других языках и иные варианты имен. Эта информация используется при добавлении работ и позволяет эффективно привязать их авторов к нужным исследователям в системе.
В системе обрабатывается информация о результатах научной и педагогической деятельности следующих типов:
• статьи в журналах;
• статьи в сборниках;
• книги;
• доклады на конференциях;
• патенты;
• свидетельства о регистрации прав на программное обеспечение;
• научные отчеты;
• членство в редколлегиях журналов;
• членство в редколлегиях сборников;
• членство в программных комитетах конференций;
• членство в диссертационных советах;
• руководство и авторство диссертаций;
• руководство дипломными работами;
• авторство учебного курса;
• преподавание (чтение) учебного курса.
Этот список постепенно расширяется.
Отметим, что одним из главных результатов научной деятельности является публикация. Многие ученые имеют значительное количество публикаций, поэтому крайне важно обеспечить удобный интерфейс ввода сведений о своих работах, позволяющий заносить данные в систему за минимальное время. Для этого в систему ИСТИНА включен модуль распознавания библиографической ссылки (рис. 1), основанный на программе Freecite (http://freecite.library.brown.edu/). Он позволяет автору не заполнять большое число полей, как во многих других системах, а указать одну или несколько библиографических ссылок на свои публикации в виде текстовых строк, и на втором шаге добавления соответствующие поля уже будут автоматически заполнены. Пользователю остается лишь проверить корректность разбора и при необходимости исправить ошибки (рис. 2).
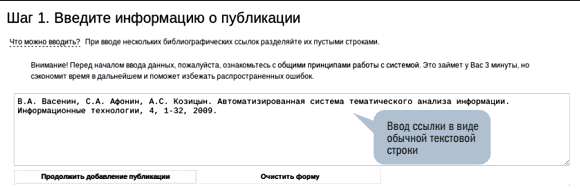
Рис. 1. Добавление работы в систему ИСТИНА, шаг 1 – разбор данных

Рис. 2. Добавление работы в систему ИСТИНА, шаг 2 – редактирование данных
На третьем шаге (рис. 3) выполняется привязка имен авторов работы к объектам (научным сотрудникам) в базе данных. Система предлагает найденных похожих сотрудников и, если алгоритм позволяет сделать однозначный выбор, то выбирает одного из сотрудников по умолчанию. Если же в базе найдено несколько ученых с высокой степенью похожести на имя одного из авторов публикации, то пользователю предлагается сделать выбор самостоятельно. Он также может исправить выбор системы. Для того чтобы облегчить выбор нужного похожего сотрудника, пользователь может оперативно, не покидая страницу, просмотреть краткую информацию о каждом из найденных сотрудников-кандидатов для выбора. Более подробное описание алгоритма подбора похожих ученых в базе данных для заданного имени автора представлено выше.

Рис. 3. Добавление работы в систему ИСТИНА, шаг 3 – привязка авторов
Многие исследователи ведут список своих работ в электронном виде, например• в файле на персональном компьютере или в различных информационных системах. Для того чтобы им не приходилось вручную повторно вводить свои данные в систему ИСТИНА, в ней предусмотрены механизмы импорта данных. Поддерживаются следующие форматы и источники:
• библиографические ссылки, упомянутые ранее;
• BibTeX;
• Web of Knowledge / Web of Science;
• Scopus;
• GoogleScholar;
• esearcherID.com;
• PubMed;
• MathSciNet;
• ZentralblattMath;
• MathNet.ru;
• веб-сайты издательств, например Elsevier, Springer и других.
При необходимости пользователь может не применять функции разбора или импорта и заполнить поля вручную. При этом вне зависимости от того, какой способ ввода данных используется, для каждой работы пользователю необходимо пройти второй шаг добавления (проверка корректности заполнения полей) и третий шаг (привязка авторов к сотрудникам в системе). При вводе публикаций к ним можно добавить аннотации и прикрепить файлы, например, с полным текстом работы или с сопутствующими материалами.
Важной особенностью системы является однократный ввод данных. Это означает, что при добавлении новой работы одним из пользователей она одновременно появляется на страницах и у всех остальных соавторов работы. При этом пользователи легко могут заметить появление новой работы, которую добавил их соавтор, на специальной странице «мои последние добавленные работы». В случае неправильной привязки публикации соавтором пользователь может отказаться от ее авторства, и она пропадет с его страницы.
Отображение данных в открытом доступе
Одним из основополагающих принципов системы ИСТИНА является открытость информации. Сведения о работах, добавляемые пользователями системы, открыты для просмотра всем пользователям интернета. Для этого не требуется регистрация. Однако некоторые статистические отчеты, касающиеся подразделений и организации в целом, доступны только руководителям этих подразделений и организации. Для реализации политики разграничения доступа к функциям системы используется механизм модераторов, прикрепленных к вершинам дерева подразделений организации. Доступными для просмотра всеми пользователями интернета являются следующие страницы:
• страница сотрудника с краткой информацией о нем и списком всех его добавленных работ (рис. 4);

Рис. 4. Страница сотрудника в системе ИСТИНА
• страница организации/подразделения со списком всех зарегистрированных в системе ее сотрудников и краткой информацией о каждом из них (рис. 5);

Рис. 5. Страница со списком сотрудников организации в системе ИСТИНА
• страница со списком всех добавленных в систему работ сотрудниками организации/подразделения за последнее время (по умолчанию − за последние две недели);
• страница со списком всех добавленных в систему работ за последний месяц;
• страница работы (например, публикации) с полной информацией о ней (рис. 6);
• страница связанного с работами объекта, например, конференции, журнала и других;
• страница поиска сотрудников и публикаций;
• различные вспомогательные страницы, например, руководство для пользователя.

Рис. 6. Страница публикации в системе ИСТИНА
Формирование отчетов и экспорт данных для сотрудников
Одним из преимуществ системы ИСТИНА является то, что она облегчает пользователям выполнение некоторых рутинных задач, неизбежно возникающих в процессе научной работы. К таким задачам, в частности, относятся: подача заявок на проекты и гранты; формирование научных отчетов в своей организации. Для решения первой задачи в системе предусмотрена возможность отображения списка своих публикаций в различных стилях, например, в алфавитном порядке (стиль «plain»), с сокращением инициалов авторов и названий журналов (стиль «abbrv»), с использованием в качестве указателей не порядковых номеров публикаций в списке, а первых букв фамилий авторов и года публикаций (стиль «alpha») и других шести стилях. В системе есть возможность экспорта сведений об отдельной публикации в форматы BibTeX, EndNote, RIS, Word, ISI и ADS и экспорта списка публикаций в формат BibTeX. Отметим, что эти форматы поддерживаются в большинстве распространенных систем для работы с библиографическими данными, что облегчает ученому повторное использование информации, введенной в систему ИСТИНА.
Система ИСТИНА позволяет формировать отчеты сотрудников на основе введенных данных. В настоящее время поддерживается два вида отчетов − годовой отчет и информационный лист. Годовой отчет (рис. 7) содержит перечень результатов научной деятельности за текущий календарный год, которые были введены в систему. Данная информация может использоваться при подаче сотрудниками годовых научных отчетов в своих подразделениях.
Информационный лист (рис. 8) включает краткую информацию о сотруднике и его деятельности за последние 5 лет, в том числе количество опубликованных статей и монографий, библиометрические показатели (например, количество цитирований его статей, индекс Хирша), краткие сведения о членстве в редколлегиях журналов и сборников, программных комитетах конференций, диссертационных советах, информация о преподавательской деятельности, то есть о прочитанных за 5 лет учебных курсах. Информационный лист может использоваться в качестве документа для процедуры переизбрания сотрудника на научно-преподавательские должности в своем подразделении. Отметим, что информационный лист формируется не с помощью веб-интерфейса системы, как остальные страницы, а путем полностью автоматического создания и компиляции TeX-файла с соответствующими данными. Именно поэтому он выглядит более приближенным к настоящим отчетам, используемым в научных организациях.

Рис. 7. Годовой отчет сотрудника в системе ИСТИНА

Рис. 8. Информационный лист сотрудника в системе ИСТИНА
Анализ статистических показателей по подразделениям и по тематикам
Важной функцией системы ИСТИНА для руководителей является возможность анализа научной деятельности сотрудников и подразделений. В качестве параметров анализа выступают следующие характеристики.
1. Тип публикации:
• статьи в журналах, входящих в число лучшие 25% журналов по импакт-фактору в своей тематической рубрике согласно данным базы Thomson Reuters Journal Citation Reports (http://thomsonreuters.com/products_services/science/science_products/a-z/journal_citation_reports/);
• статьи в журналах, включенных в базу Thomson Reuters Journal Citation Reports;
• статьи в журналах, включенных в базу Scopus;
• статьи в любых журналах;
• статьи в сборниках трудов конференций (исключая тезисы);
• все публикации.
2. Статус публикации:
• проверенные публикации, то есть публикации, корректность выходных данных которых была вручную проверена и подтверждена специально назначенными ответственными сотрудниками;
• все публикации.
3. Год публикации:
• публикации, вышедшие в печать в 2012 г.;
• публикации, вышедшие в печать в 2011 г.;
• публикации, вышедшие в печать в 2010 г.;
• все публикации.
4. Подразделение, в котором работает сотрудник − автор публикации: для анализа можно отобрать подразделение, находящееся на любом уровне структурной иерархии.
5. Тематика журнала, в котором опубликована работа: для анализа можно отфильтровать публикации по тематике журнала. В системе поддерживается два рубрикатора: Scopus и ГРНТИ.
6. Метрика, то есть количественная характеристика, по которой рассчитываются показатели отдельных подразделений и тематических направлений:
• общее число публикаций, удовлетворяющих критериям поиска;
• общее число цитирований публикаций по данным Web of Science;
• число цитирований публикаций по данным Web of Science в расчете на одного автора;
• число сотрудников − авторов публикаций;
• сумма коэффициентов вкладов авторов − сотрудников подразделения, где вклад одного автора рассчитывается как единица, деленная на число авторов работы;
• взвешенная сумма коэффициентов вкладов авторов − сотрудников подразделения, которая отличается от предыдущей характеристики тем, что дополнительно учитывается позиция журнала, в котором опубликована работа, по импакт-фактору в своей тематической рубрике по данным Web of Science. Данная метрика позволяет учитывать все статьи в журналах из Journal Citation Reports, придавая большее значение публикациям в журналах с высоким импакт-фактором.
Комбинируя значения перечисленных параметров, руководитель организации или подразделения может получить большое число различных статистических данных по интересующим его подразделениям и тематикам. Результаты анализа представляются в виде списков и диаграмм. Например, для оценки работы различных подразделений с помощью описанного инструментария можно вывести следующие данные:
• отсортированный список подразделений по количеству цитирований публикаций их сотрудников за отчетный период (рис. 9), при необходимости учитывая рейтинг соответствующего журнала по импакт-фактору;
• отсортированный список подразделений по общему количеству публикаций сотрудников за отчетный период;
• распределение тематик по суммарному числу цитирований публикаций (рис. 10), что позволяет оценить наиболее развитые области научного знания в организации.
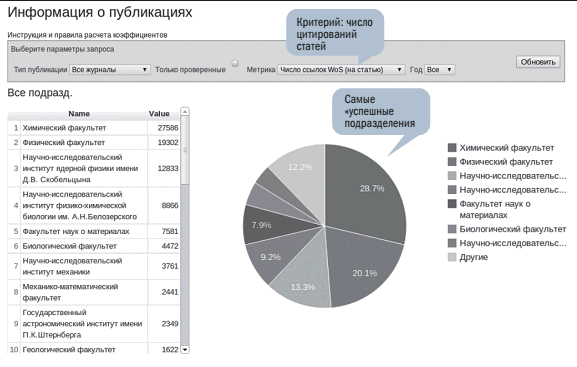
Рис. 9. Распределение подразделений МГУ по критерию числа цитирований статей с авторством сотрудников МГУ
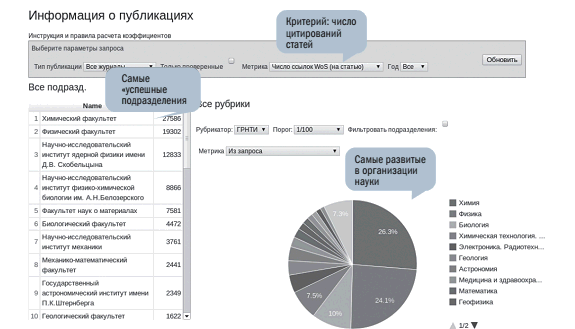
Рис. 10. Распределение областей знаний по критерию числа цитирований статей под авторством сотрудников МГУ
Кроме оценки подразделений, рассматриваемое средство позволяет проанализировать выбранную тематику, то есть область научного знания. Например, можно вывести список подразделений, сотрудники которых опубликовали наибольшее количество статей в журналах физического профиля за отчетный период (рис. 11). При этом также отображается разбиение соответствующих статей по подразделам заданной тематики в рамках используемого рубрикатора. Такие статистические отчеты позволяют составить общее представление о развитии рассматриваемого тематического направления в организации в целом и в ее отдельных подразделениях, а также понять, какие из подразделов заданной области знания развиваются в организации наиболее активно, а какие, наоборот, переживают стагнацию.
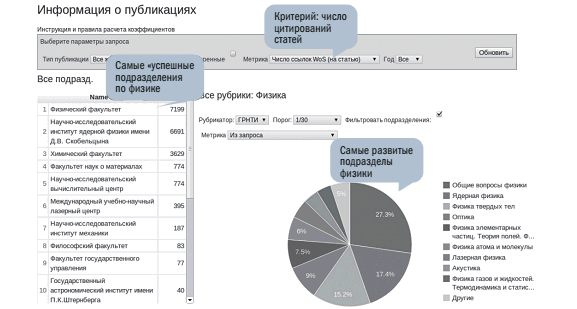
Рис. 11. Распределение подразделений МГУ и подразделов физики по критерию числа цитирований статей по физике с авторством сотрудников МГУ
Отметим, что в настоящее время средства анализа в системе во многом ориентированы на естественно-научные специальности. Такое положение обусловлено тем обстоятельством, что анализу подвергаются только публикации в журналах и сборниках трудов конференций. Однако для многих гуманитарных специальностей наиболее ценными показателями результативности труда служат другие виды работ. Например, для филологов это могут быть переводы книг, для историков – монографии, для журналистов – статьи в газетах с большим тиражом. Как следствие, одним из приоритетных направлений развития системы ИСТИНА является разработка средств, которые будут позволять различным подразделениям и организациям устанавливать свои критерии анализа, учитывающие специфику их предметной области. Первым шагом в этом направлении является расширение списка типов результатов научной деятельности, которые можно добавлять в систему. Отметим, что в текущей версии таких типов уже 15, что выгодно отличает ИСТИНУ от других распространенных систем, учитывающих главным образом публикации. Вторым шагом является расширение возможностей количественного и тематического анализа работ. В настоящее время анализ выполняется только по публикациям и никак не учитывает, например, членство в редколлегиях журналов и диссертационных советах, а ведь эти виды деятельности являются очень важными при оценке труда ученого. Однако нельзя не отметить, что система ИСТИНА позволяет просмотреть страницу любого сотрудника и вручную оценить его деятельность уже по всем 15 возможным типам работ, включая членство в редколлегиях журналов и диссертационных советах.
Для организации и наглядного представления всех сущностей и связей, характеризующих научную деятельность, в системе используется онтология, то есть формальная модель представления знаний, основанная на дескриптивной логике. Общая схема системы, включающая онтологии, представлена на рисунке 12. В частности, в онтологии области научной деятельности перечислены все типы работ, обрабатываемые в программном комплексе, связи между ними и учеными, конференциями, журналами и другими сущностями. В системе ИСТИНА онтология является расширением активно используемой онтологии Semantic Web for Research Communities (SWRC) [3]. В будущем предполагается разработать средство, которое позволит представителям различных подразделений самим формировать части онтологии, отвечающие за формулирование критериев, которые позволяют оценить деятельность их сотрудников. Затем по этим частям онтологии будут автоматически или в автоматизированном режиме формироваться запросы к системе и результаты их выполнения. Это позволит вычислять более широкий спектр запросов к данным системы и создавать разнообразные аналитические отчеты, не затрагивая при этом ее программный код.
Онтологии могут использоваться и для другой цели, а именно, для тематического анализа результатов научной деятельности. Для этого необходимо построить онтологию отдельной области научного знания (рис. 12), например математики, которая должна содержать основные направления, понятия и связи между ними. Такую онтологию можно использовать двумя способами. Во-первых, она позволит расширить возможности анализа деятельности подразделений и организаций по тематикам. В настоящее время в качестве источника информации о тематиках используются рубрикаторы, причем тематика публикации определяется по фиксированной тематике журнала, в котором опубликована статья. Использование онтологий вместо рубрикаторов позволит более точно определить тематику конкретной работы, так как предполагается, что онтология содержит большее число понятий и отношений, чем рубрикатор, а кроме того, к понятию из онтологии будет привязана каждая отдельная публикация, а не целый журнал. Во-вторых, использование онтологий позволит добавить в систему такие функции, как отображение списка работ, похожих на заданную, списка ученых, занимающихся близкой тематикой, списка похожих журналов, и другие тематические запросы. Для эффективного выделения терминов из полуструктурированных текстов и автоматизированного формирования онтологий предметных областей авторами разработаны алгоритмы Brainsterm [4] и Sonmake [5]. В настоящее время для системы ИСТИНА разрабатываются и тестируются рассмотренные средства тематического анализа, основанные на использовании онтологий.
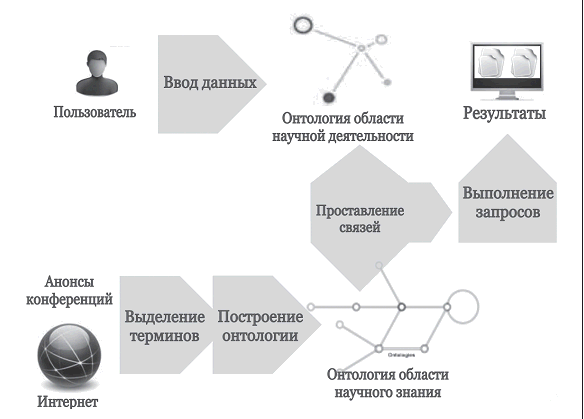
Рис. 12. Общая схема использования онтологий в системе ИСТИНА
Заключение
Основными преимуществами системы ИСТИНА по сравнению с другими системами, предназначенными для управления научной информацией, являются:
- высокая точность и полнота данных в рамках организации;
- контроль пользователей над данными;
- удобство ввода информации;
- формальная модель, на основе которой разработана система;
- наличие полезных для сотрудников функций;
- широкие возможности анализа деятельности для руководителей.
С мая 2012 г. система ИСТИНА внедряется в МГУ им. М.В. Ломоносова по адресу http://istina.imec.msu.ru. Система используется для анализа деятельности сотрудников и подразделений, а также в двух формальных процедурах в рамках университета: для распределения поощрительных надбавок сотрудникам за публикации в высокорейтинговых журналах, а также для формирования информационных листов для переизбрания сотрудников на научно-преподавательские должности. В системе зарегистрировано более 6800 сотрудников университета из 750 подразделений. Они добавили в систему более 200 тыс. статей, 14 тыс. книг, 24 тыс. докладов на конференциях, 2.5 тыс. патентов, 1.6 тыс. научных отчетов, 1.5 тыс. случаев членства в редколлегиях журналов, 1.4 тыс. − в редколлегиях сборников, 2 тыс. − в программных комитетах конференций, 1 тыс. − в диссертационных советах, 6 тыс. диссертаций, защищенных в 2.5 тыс. диссертационных советах, 7.7 тыс. дипломных работ и 5.5 тыс. учебных курсов.
В дальнейшем планируется добавить в систему новые виды деятельности для учета (например, географические атласы, газеты, национальные премии), расширить возможности анализа с помощью онтологий, добавить средства выявления тенденций развития областей науки. Предполагается расширить спектр применения системы в МГУ им. М.В. Ломоносова, а также предоставить доступ к ней другим научным и образовательным организациям Российской Федерации. Когда в системе ИСТИНА будут зарегистрированы крупнейшие российские научные и образовательные учреждения, у руководителей межведомственных структур появятся новые возможности:
- построить информационную карту российской науки по отраслям с детализацией по регионам, организациям и конкретным ученым;
- формировать аналитические отчеты, например: «самые успешные организации / ученые в заданной научной отрасли», «научные отрасли, в которых успешно работает заданная организация» и другие, аналогичные им;
- выявлять и анализировать тенденции развития организаций, регионов и страны в целом по отдельным разделам науки с течением времени.
Литература
1. Левенштейн В.И. Двоичные коды с исправлением выпадений, вставок и замещений символов // ДАН СССР. 1965. № 163 (4). С. 845–848.
2. Ratcliff J.W., Metzener D., et al. Patternmatching: Thegestalt approach // Dr. Dobb’s Journal. 1988. T. 7. С. 46.
3. Sure Y., Bloehdorn S., Haase P., Hartmann J., Oberle D. The swrc ontology – semantic web for research communities // Proceedings of the 12th Portuguese Conference on Artificial Intelligence – Progress in Artificial Intelligence (EPIA 2005). 2005. Covilha: Springer, LNCS. Т. 3803. С. 218–231.
4. Голомазов Д.Д. Выделение терминов из коллекции текстов с заданным тематическим делением // Информационные технологии. 2010. № 2. С. 8–13.
5. Васенин В.А., Афонин С.А., Голомазов Д.Д. К созданию системы управления научной информацией на основе семантических технологий // Материалы Всероссийской конференции с международным участием “Знания – Онтологии – Теории” (ЗОНТ-2011), 3–5 октября 2011 г. Институт математики им. С.Л. Соболева СО РАН. Новосибирск, 2011. Т. 1. С. 78–87.
___________________________________________________
Васенин Валерий Александрович - д.ф.-м.н., профессор, заведующий отделом Института проблем информационной безопасности МГУ имени М.В. Ломоносова
e-mail: vasenin@msu.ru
Афонин Сергей Александрович - к.ф.-м.н, ведущий научный сотрудник НИИ механики МГУ имени М.В. Ломоносова
e-mail: serg@msu.ru
Голомазов Денис Дмитриевич - к.ф.-м.н., научный сотрудник НИИ механики МГУ имени М.В. Ломоносова
e-mail: denis.golomazov@gmail.com
Козицын Александр Сергеевич - к.ф.м.н., ведущий научный сотрудник НИИ механики МГУ имени М.В. Ломоносова
e-mail: aleksanderkz@mail.ru
© Информационное общество, 2013 вып. 1-2, с. 38-57.