О журнале
Рекомендации
«Вычислительное облако» как средство эффективной организации вычислительных ресурсов в центре обработки научных данных
В.В. Коноплев, Р.Р. Назиров
обработки научных данных
_________________
В.В. Коноплев, Р.Р. Назиров
Аннотация
В статье рассматриваются вопросы эффективной организации вычислительных ресурсов в центре обработки научных данных с применением технологий облачных вычислений, в частности, парадигмы «инфраструктура как сервис». Обсуждаются технологические подходы, которые при ограниченном бюджете позволяют строить решения, обладающие характеристиками систем корпоративного уровня.
Ключевые слова: облачные вычисления, виртуализация, OpenStack, ZFS, Infiniband.
На пути к облачным технологиям
Современные тенденции, прослеживаемые в индустрии информационных технологий, лишний раз подтверждают, что мир развивается по спирали, а новое – это зачастую хорошо забытое старое. Так, принцип коллективного использования вычислительных ресурсов, реализованный на базе «больших ЭВМ» в 1960-х годах, на рубеже 1980–1990-x годов с появлением персональных компьютеров был временно забыт, но теперь приобретает популярность уже в новом качестве.
Благодаря персональным компьютерам пользователи вычислительных систем в полной мере смогли насладиться свободой, которую дает понятие «персональный». Однако персональные устройства принесли с собой и персональные хлопоты, связанные с обслуживанием аппаратного и программного обеспечения, информационной защитой, резервированием данных, – все то, что раньше входило исключительно в должностные обязанности системных администраторов. Другим недостатком персональных компьютеров является низкая эффективность их использования. С одной стороны, производительности персонального компьютера часто не хватает для решения сложных вычислительных задач, с другой стороны, большую часть времени персональный компьютер простаивает. Поэтому уже с конца 1980-х годов начался обратный процесс, связанный с консолидацией вычислительных ресурсов в общедоступные пулы для решения пользовательских задач. Можно выделить три основные вехи данного процесса: формирование распределенных систем управления пакетными заданиями, Грид-вычисления и облачные вычисления.
Распределенные системы управления пакетными заданиями появились в конце 1980-х годов с целью задействовать простаивающие процессоры рабочих станций. Центральный диспетчер находил в сети свободные компьютеры и загружал на них части общего вычислительного процесса. Как только хозяин компьютера садился за консоль, запущенное задание приостанавливалось либо переносилось на другой свободный вычислительный узел. Именно по такому принципу работала одна из первых систем CONDOR [1], получившая широкое распространение.
Модель Грид-вычислений является развитием распределенного управления пакетными заданиями. Она привнесла ряд архитектурных решений, которые способствовали повышению масштабируемости, надежности и безопасности. К ним можно отнести иерархическую модель администрирования с использованием понятия «виртуальная организация», подсистему безопасности на основе сертификатов с открытым ключом и возможностью временного делегирования полномочий, а также мощный язык описаний, позволяющий точно декларировать требования к вычислительному окружению пакетного задания. Фактически модель Грид-вычислений впервые обеспечила возможность построения глобальных сетей общедоступных пулов вычислительных ресурсов с авторизацией доступа и балансированием нагрузки. Данный подход был с энтузиазмом встречен в научном сообществе, поскольку предоставил широкие перспективы кооперации при использовании вычислительных мощностей научных центров. С развитием Грид-технологий стала формироваться концепция «вычисление как сервис». Адепты Грид-технологий часто сравнивали вычислительную инфраструктуру с электрической сетью, к которой можно просто подключиться подобно тому, как мы включаем утюг. Однако по своей сути Грид-вычисления остаются средством запуска пакетных заданий, а значит, не подходят для большинства типовых задач. В частности, у пользователя Грид-систем нет возможности работать с интерактивными приложениями, как и с приложениями-сервисами.
Облачные вычисления предлагают альтернативный подход к консолидации и совместному использованию вычислительных ресурсов, который свободен от недостатков, присущих Грид-вычислениям. В настоящее время уже нельзя отрицать, что облачные вычисления являются перспективным и быстро развивающимся направлением, а полученные результаты с успехом применяются для повышения эффективности совместного использования больших пулов вычислительных ресурсов. Это представляется особенно привлекательным для тех областей научных вычислений, где зачастую время жизни проектов оказывается меньше, чем время жизни вычислительных систем, приобретаемых для их реализации. Таким образом, формируются свободные вычислительные мощности, которые можно и нужно уметь эффективно консолидировать для решения новых научных задач. Понятие «облачные вычисления» не ограничивается какой-то определенной моделью или технологией. Это, скорее, набор парадигм по организации совместного доступа к вычислительным и программным ресурсам, а именно: «программное обеспечение как сервис», «платформа как сервис» и «инфраструктура как сервис». Последняя парадигма – «инфраструктура как сервис» – предоставляет пользователю возможность самому управлять элементами вычислительной инфраструктуры: ресурсами обработки и хранения, а также сетевыми ресурсами. Как правило, в рамках парадигмы «инфраструктура как сервис» пользователь получает доступ не к исходным физическим элементам инфраструктуры, а к их виртуальным представлениям. Это позволяет эффективно решать вопросы безопасности и совместного использования физических ресурсов. Кроме того, появляется возможность миграции пользовательских процессов с целью балансирования нагрузки или повышения доступности пользовательских сервисов.
Облачные технологии в центре обработки научных данных
Специфика информационных проектов в научных областях несколько отличается от проектов в области бизнес-приложений. Требования к гарантиям качества обслуживания и уровню доступности сервисов здесь, как правило, ниже. В тоже время для успешной реализации проекта зачастую требуется при ограниченном бюджете получить максимальные характеристики по производительности и/или объемам хранения. По этой причине научные информационные проекты целесообразно внедрять на базе компьютерных элементов широкого потребления, что в англоязычных источниках называется commoditycomputing. Отказоустойчивость и другие специализированные функции в этом случае реализуются на программном уровне. Такой подход значительно уменьшает стоимость проекта, но даже в этом случае для успешного выполнения научной миссии иногда приходится подключать оборудование смежных проектов и даже задействовать вычислительные ресурсы партнерского научного центра.
В этой связи вполне органичным представляется развертывание центра обработки научных данных на базе платформы «инфраструктура как сервис» (IAAS) с использованием открытого промежуточного программного обеспечения (ППО). В настоящее время существует несколько открытых программных проектов для создания облачных инфраструктур IAAS: Eucaliptys[2],OpenStack [3], CloudStack [4]. Наиболее зрелым на данный момент выглядит проект OpenStack, стартовавший в 2010 г. в результате слияния проектов Nebula (организации NASA) и CloudFilesplatform (компании Rackspace). На его фоне свободная версия Eucaliptys отстает в функциональности, а сравнительно молодой проект CloudStack еще недостаточно стабилен.
Архитектурно OpenStack представляет собой ряд функциональных сервисов, взаимодействующих посредством сервера сообщений и центрального реестра на базе реляционной СУБД (рис. 1). В состав OpenStack входят перечисленные ниже компоненты.
1. Keystone – сервис аутентификации и авторизации на базе механизма токенов. Объектная модель сервиса Keystone поддерживает «многодоменность», что способствует масштабируемости на уровне подключаемых пользователей и организаций.
2. Nova – сервис вычислений, управляющий жизненным циклом виртуальных машин. Он включает следующие компоненты:
• Nova-compute – управляет экземплярами виртуальных машин и поддерживает все основные гипервизоры;
• Nova-network – настраивает сетевое окружение для виртуальных машин;
• Nova-scheduler – планировщик ресурсов, выбирает подходящий узел для запуска виртуальной машины;
• Nova-volume – сервис блочных устройств для расширения дискового пространства виртуальных машин.
3. Glance – сервис образов, управляет хранением образов, из которых потом разворачиваются виртуальные машины на вычислителях.
4. SWIFT – параллельное отказоустойчивое объектное хранилище, которое может использоваться, в частности, совместно с сервисом Glance для хранения образов виртуальных машин.
Механизм взаимодействия компонент OpenStack наилучшим образом можно продемонстрировать на примере запуска виртуальной машины. С консоли управления поступает команда, которая через сервер сообщений передается планировщику nova-scheduler. Планировщик находит подходящий вычислительный сервер (вычислитель) и передает управление работающему на нем агенту nova-compute. Агент nova-compute обращается к сервису образов Glance и загружает на вычислитель образ виртуальной машины. Затем он подготавливает на вычислителе образы виртуальных дисков и дает команду гипервизору на запуск виртуальной машины. Далее к работающей виртуальной машине посредством компоненты nova-volume могут быть подключены дополнительные тома, расположенные на блочном хранилище.
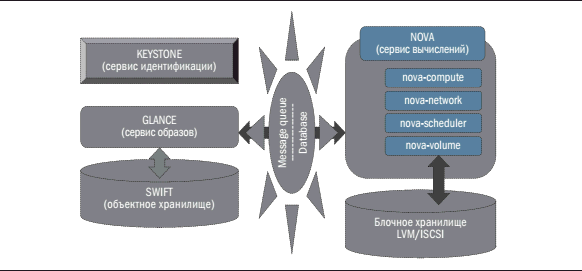
Рис. 1. Архитектура OpenStack
Технология Infiniband как перспективное межсоединение для организации облачных сервисов
Удачный выбор технологии и структуры межсоединений является одним из ключевых факторов, влияющих на производительность центров обработки данных. Эта проблема становится особенно острой, если межсоединение выполняет также функции транспорта для дискового ввода-вывода.
Сейчас наиболее распространенной технологией для организации высокопроизводительных межсоединений в пределах ЦОД является семейство стандартов 10GigabitEthernet (10 GE). Технология 10GE родственна семейству технологий Ethernet, являющихся в настоящее время стандартом для построения локальных вычислительных сетей. По этой же причине технология 10GE обладает наилучшей конвергенцией с сетевыми сервисами и оборудованием межсетевого обмена.
Технология Infiniband до недавнего времени рассматривалась как сравнительно дорогое, «элитное» решение, используемое исключительно в высокопроизводительных вычислениях (HPC). В настоящее время технология Infiniband стала позиционироваться как средство доступа к хранилищам данных [5]. Технология прямого удаленного доступа к памяти (RDMA), поддерживаемая стандартом Infiniband, обладает рядом преимуществ, таких как низкие задержки и отсутствие нагрузки на центральные процессоры. Это позволяет получить производительность работы удаленных хранилищ, сравнимую с локальными дисковыми системами. Развитая функциональность промежуточного стека протоколов и сервисов, который также является частью стандарта Infiniband, позволяет использовать данную технологию для решения широкого круга прикладных задач, включая обмен сообщениями, удаленный доступ к блочным устройствам, удаленный доступ к последовательным устройствам, эмуляция IP-сетей. В отличие от технологии 10 GE, технология Infiniband позволяет строить сложные сетевые топологии с избыточностью, альтернативными активными путями и балансировкой нагрузки.
Технология Infiniband как межсоединение для HPC по производительности в несколько раз превосходит технологии ЛВС. Это дает возможность на текущем временном срезе использовать не последнюю активно продвигаемую на рынке спецификацию Infiniband (на данный момент это QDR 40 Gbit/s), а предыдущие (SDR 10 Gbit/s или DDR 20 Gbit/s), которые находятся в конце жизненного цикла и по этой причине доступны со значительными скидками. Ниже в таблице 1 приведены приблизительные сравнительные данные о стоимости инсталляции при использовании технологий IBDDR4x20Gbit/s и 10 GE 10Gbit/s.

Таблица 1. Сравнительная стоимость инсталляции оборудования (тыс. рублей)
Из таблицы видно, что технология IBDDR 4x, обладая в 2 раза большей пропускной способностью, стоит заметно меньше, что в итоге дает выигрыш в 2,5 раза в соотношении пропускной способности к стоимости. Технология RDMA, заложенная в стандарте Infiniband, делает эту разницу еще более заметной. В частности, для систем хранения тесты производителей показывают, что RDMA позволяет до 2 раз улучшить такие характеристики, как скорость обмена, количество операций в секунду и время выполнения операции. Таким образом, совокупный выигрыш в отношении стоимости к производительности получается до 5 раз и более для крупных инсталляций со сложными сетевыми топологиями, где Infiniband способен также оптимизировать маршруты, а Ethernet будет работать по схеме «общее дерево» (Spanning Tree).
Текущие проблемы организации централизованных хранилищ данных для облачных сервисов и их решение на базе файловой системы ZFS
Активное внедрение технологий виртуализации и парадигмы «инфраструктура как сервис» предъявляют новые требования к характеристикам систем хранения данных. Консолидация вычислительных ресурсов обеспечивает работу оборудования в жестком многопользовательском режиме, причем нагрузка на него ощутимо возрастает. Проблема усложняется тем, что мы не можем произвести оптимизацию вычислительной системы под конкретную задачу или определенный профиль нагрузки, будь то транзакционная СУБД со случайным профилем доступа или файловый архив – с последовательным. Одновременно существует потребность удобно и безопасно перераспределять незадействованное дисковое пространство между пользователями. Возможность такого перераспределения мы будем называть преемственностью.
Таким образом, централизованная система хранения данных для облачных вычислений должна обеспечивать:
• высокую степень преемственности свободного пространства между пользователями;
• высокую производительность по основному набору параметров (пропускная способность, количество операций в секунду, время операции);
• высокую скорость работы с метаданными (поиск, удаление и передвижение файлов);
• удовлетворительную работу на разных типах нагрузок, а также на комбинированных нагрузках.
Текущие параллельные файловые системы, обладая, на первый взгляд, привлекательными характеристиками, не всегда являются подходящим решением для облачных вычислений. Так, параллельная файловая система Lustre [6] требует довольно сложной инсталляции, имеет повышенные накладные расходы при работе с метаданными и не масштабируется в области работы с метаданными. Кроме того, Lustre не поддерживает избыточность по данным. Другой вариант – GlusterFS [7] – обладает сравнительно низкой производительностью и устойчивостью.
Для небольших и средних инсталляций файловая система ZFS [8] представляется удачным решением, обладая приведенным ниже набором важных характеристик.
1. Устойчивость. ZFS была анонсирована компанией SUNMicrosystemsInc. в 2004 г. и к настоящему моменту является основной файловой системой в ОС Solaris и FreeBSD.
2. Функциональность управления данными. Файловая система ZFS совмещает в себе функции программного RAID-а, менеджера томов и файловой системы. Она позволяет в рамках одного дискового пула организовывать «наборы данных» (dataset) и монтировать их как узлы виртуальной файловой системы. Для каждого набора данных ZFS позволяет задавать величину квоты и резервирования. Благодаря этому перераспределение дискового пространства между пользователями осуществляется простым изменением этих двух параметров. Кроме того, для каждого набора данных ZFS позволяет создавать неограниченное количество снимков (snapshot) и задавать индивидуальные настройки, такие как размер блока данных.
3. Производительность. Файловая система ZFS реализует ряд инновационных технологий, которые выгодно отличают ее от конкурентных разработок. Сюда входят адаптивный замещающий КЭШ (ARC), многоуровневый КЭШ на базе твердотельных дисков (L2ARC), промежуточная фиксация синхронной записи (intentlog).
4. Надежность. ФС ZFS поддерживает функции избыточности (mirror, raidz) и двойной избыточности (raidz2), благодаря чему является устойчивой к отказам отдельных дисков. ФС ZFS была спроектирована так, чтобы работать непосредственно с дисками и устранить единую точку отказа в виде аппаратного контроллера RAID.
Особенности развертывания OpenStack в ЦОД ИКИ РАН
Развернутый в ЦОД ИКИ РАН пилотный проект по внедрению облачной платформы «инфраструктура как сервис» базируется на трех описанных ранее ключевых технологиях: ППО OpenStack, межсоединение на базе Infiniband спецификации 4xDDR и централизованное разделяемое хранилище данных на базе файловой системы ZFS. Функции контроллера облака и хранилища данных сосредоточены на центральном многодисковом сервере с объемом 40ТБ полезного дискового пространства и высокопроизводительным твердотельным дисковым КЭШем размером 360ГБ. В пространстве ZFS организованы наборы данных для объектного хранилища образов виртуальных машин,
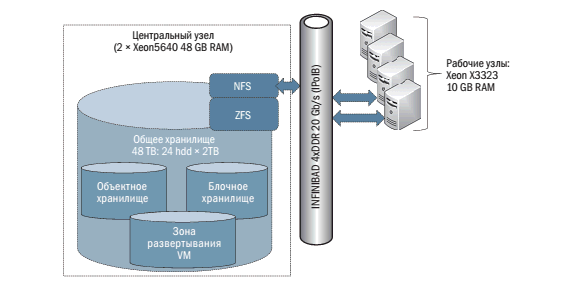
Рис. 2. Схема развертывания «облачной» платформы в ЦОД ИКИ РАН
Проведенные тесты показали, что скорость работы виртуальных дисков в зоне развертывания виртуальных машин достигает 220МБ/с, а скорость работы с томами блочного хранилища – 160 МБ/c. Таким образом, скорость работы с центральным хранилищем оказалась соизмерима с производительностью локальных дисковых систем.
В настоящей работе представлен один из вариантов построения вычислительного облака, реализованный в ЦОД ИКИ РАН. К сожалению, ограниченный объем публикации не позволяет провести сравнительный анализ альтернативных подходов и продуктов для реализации парадигмы «инфраструктура как сервис». Вместе с тем предложенный подход с использованием технологической триады OpenStack, Infiniband и ZFS показал, что даже при ограниченном бюджете можно создавать технологические решения, обладающие характеристиками систем корпоративного уровня.
Работа выполнена при поддержке программы Президиума РАН № 14.
ЛИТЕРАТУРА
1. Litzkow M., Livny M., Mutka M. Condor - A Hunter of Idle Workstations // Proceedings of the 8th International Conference of Distributed Computing Systems. June, 1988. Р. 104–111.
2. Open Source Private and Hybrid Clouds from Eucalyptus //
URL:http://www.eucalyptus.com/ (дата обращения: 14.01.2013).
3. OpenStack Open Source Cloud Computing Software //
URL:http://www.openstack.org/ (дата обращения: 14.01.2013).
4. Apache CloudStack (Incubating): Open Source Cloud Computing //
URL: http://incubator.apache.org/cloudstack/ (дата обращения: 14.01.2013).
5. Building a Scalable Storage with InfiniBand //Mellanox Technologies whitepaper.2012 //
URL:http://www.mellanox.com/related-docs/whitepapers/WP_Scalable_Storage_InfiniBand_Final.pdf
(дата обращения: 14.01.2013).
6. Luste File System: High-Performance Storage Architecture andScalable Cluster FileSystem // Sun Microsystems whitepaper. 2007 //
URL: http://www.cse.buffalo.edu/faculty/tkosar/cse710/papers/lustre-whitepaper.pdf
(дата обращения 14.01.2013).
7. GlusterFS //
URL: http://www.gluster.org/(дата обращения: 14.01.2013).
8. ZFS: [страница Википедии] //
URL: http://ru.wikipedia.org/wiki/ZFS (дата обращения 14.01.2013).
_______________________________
Коноплев Вениамин Викторович - кандидат технических наук,
главный специалист отдела высокопроизводительных вычислительных систем и сетей ЭВМ в ИКИ РАН
Назиров Равиль Равильевич - доктор технических наук, профессор кафедры математического моделирования МИЭМ, заместитель директора ИКИ РАН Институт космических исследований Российской академии наук (ИКИ РАН).
© Информационное общество, 2013 вып. 1-2, с. 17-25.