О журнале
Рекомендации
Семантические методы структурирования математического контента, обеспечивающие расширенную поисковую функциональность
А.М. Елизаров, Е.К. Липачёв, Ю.Е. Хохлов
_____________________________________
А.М. Елизаров, Е.К. Липачёв, Ю.Е. Хохлов
Аннотация
Представлены технологии Семантического веба, позволяющие реализовать в электронных научных коллекциях сервисы с расширенной поисковой функциональностью. Отдельное место отведено математическим электронным информационным ресурсам и особенностям представления математических текстов. Описаны способы совместного использования электронных коллекций с различающейся организацией, обусловленной особенностями использования математической нотации в электронных публикациях. Предложены модель интеграции математических электронных коллекций и комплекс методов, обеспечивающих автоматическое преобразование электронных публикаций с применением систем конвертации данных, объединения схем данных, а также стилевого приведения данных из разных коллекций в единое представление. Описаны методы автоматического выделения из научных публикаций идентифицирующих метаданных и система генерации административных метаданных.
Ключевые слова: информационное общество, информационно-коммуникационные технологии, информационные ресурсы, технологии Семантического веба, электронные научные коллекции, расширенная поисковая функциональность, идентифицирующие и административные метаданные, математическая нотация в электронных публикациях, «связанные данные» (Linked Data).
В настоящее время научная деятельность характеризуется использованием информационно-коммуникационных технологий (ИКТ) практически на каждом этапе проведения исследований [1]. Электронная форма представления научных материалов для большинства ученых стала предпочтительнее бумажной, а знакомство с новыми научными результатами и общение все чаще происходят через интернет. Развитие ИКТ коренным образом изменило технологии хранения, обработки и передачи научной информации, а деловая и научная активность осуществляется преимущественно в сетевом пространстве. Новые сервисы (в том числе поисковые), непосредственно связанные с электронной формой представления информации, делают электронные научные ресурсы более привлекательными по сравнению с печатными изданиями, обрабатывать которые можно только вручную. С развитием глобальной телекоммуникационной инфраструктуры и появлением нового поколения мобильных устройств привычные книги и журналы стали менее востребованными в научной деятельности. Это подтверждают, в частности, небольшие и продолжающие падать тиражи печатных научных изданий на фоне увеличения количества электронных ресурсов. Вместе с тем научные электронные издания и ресурсы растворены в потоке электронной информации, объем которого лавинообразно растет (по некоторым данным, ежедневно появляется примерно 15 петабайт новой электронной информации, что в несколько раз превышает фонды всех библиотек).
Традиционный подход к организации хранения электронных публикаций и доступа к ним через интерфейс полнотекстовых поисковых систем является в наши дни наиболее распространенным. Однако в силу растущих объемов электронной информации, а также особенностей жизненного цикла электронных научных публикаций использование стандартных сервисов и поисковых средств интернета применительно к научной электронной информации становится все менее эффективным. Кроме того, стандартная технология полнотекстового поиска не содержит инструментов для распознавания семантических отношений между объектами знания, например, отношений между терминами или связей между математическим символом и его семантикой. Поэтому актуальным становится расширение возможностей стандартного полнотекстового поиска. Очевидно, для предоставления таких возможностей должна быть пересмотрена концепция обработки исходных документов. Реализовать сервисы с расширенной поисковой функциональностью позволяют технологии Семантического веба [2], нацеленные, в частности, на разработку средств создания и поддержки больших интегрированных баз знаний на основе унифицированных семантических моделей.
Семантические технологии расширения поисковой функциональности
Одна из центральных идей Семантического веба базируется на понятии «связанные данные» (Linked Data) [3], в основе которого лежит признание того, что первичными объектами Веба являются описания сущностей с явным указанием их семантики и семантики ссылок (отношений) между ними. Семантические связи между данными повышают их ценность и предоставляют дополнительное удобство в их использовании. В результате данные, интегрированные в единую Семантическую паутину, представляют собой пространство знаний о некоторой предметной области. Технологически этот подход обеспечивается представлением данных в виде триплетов «субъект–предикат–объект» формата RDF (Resource Description Framework), идентификацией данных с помощью универсальных идентификаторов ресурсов URI, механизмом доступа по протоколу HTTP и спецификацией контролируемых словарей на различных языках (в частности, RDFS и OWL).
Одним из первых проектов, реализуемых с 2007 г. в рамках названного подхода, является Linking Open Data (LOD) (http://www.w3.org/wiki/ SweoIG/TaskForces/CommunityProjects/LinkingOpenData). Этот проект выявил важные преимущества представления гетерогенных данных, полученных от различных контент-провайдеров, в виде единого связанного «облака». Сегодня объем данных в LOD составляет более 35 млрд. триплетов. Научные коллекции представлены в LOD в виде неофициальных наборов данных, не поддерживаемых на постоянной основе. Содержимым этих наборов являются стандартные метаданные статей (название, год публикации, информация об авторах и др.), а главное преимущество заключается в стандартизованном подходе к структурированию и хранению интегрированных данных, которые, как правило, загружаются и представляются в RDF-формате из таких традиционных хранилищ, как реляционные базы данных или (реже) веб-страницы и неструктурированные текстовые документы.
Математика и информатика являются предметными областями, где с успехом могут быть применены технологии Семантического веба. Современное математическое научное сообщество ежегодно генерирует огромные объемы полезной электронной информации в виде книг, журнальных публикаций и статей в сборниках трудов конференций, учебников и другой специализированной литературы, а представление математических знаний в виде, удобном для компьютерной обработки, является относительно новой и быстро развивающейся областью исследований. Создавать семантические модели математических документов позволяют такие формальные языки описания математических сущностей, как MathLang [4] и OMDoc [5], однако формирование строго формализованных математических документов является трудоемким процессом. В рамках же традиционного подхода к представлению и обработке математических документов игнорируются структурированность математического документа, наличие элементов математической нотации и категоризация текстов по разделам математики. Использование указанных свойств требует развития альтернативных семантических моделей математического документа, обрабатывающих, в частности, такие дополнительные характеристики, как элементы математической нотации.
На пути включения математических документов в облако LOD делаются только первые шаги, причем сегодня существует лишь несколько онтологических моделей, предоставляющих менее выразительную степень детализации математической предметной области. Ниже акцент делается на технологиях Семантического веба, которые могут применяться при интеллектуальной обработке электронных математических научных публикаций.
Особенности представления и системы подготовки
математических текстов
Как известно, в мировом информационном пространстве электронные научные публикации рассеяны по многочисленным электронным коллекциям. Электронные публикации по математике, помимо того, что они опубликованы на разных языках, имеют разнообразные формы представления и особенности использования математической нотации. По этим причинам поиск релевантных математических научных публикаций затруднен и обладает невысокой точностью.
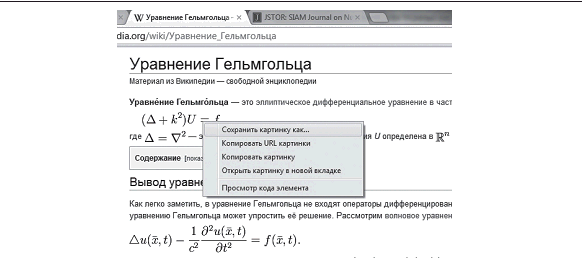
Рис. 1. Формулы в виде графических вставок
Представление математических текстов в интернете является сложной задачей, не имеющей в настоящее время стандартного и удовлетворяющего всех решения. Самой распространенной является вставка математических формул в виде графических файлов, что можно сделать с помощью конвертера LaTex2HTML, редактора MS Word или целого ряда других программных средств (рис. 1). Также используются вставка математических символов из специального шрифта (чаще всего SYMBOL) и конвертеров (например, TTH и TTMath), загрузка математических шрифтов на машину клиента, использование Java-аплетов для их отображения и вызов Java-аплетов для просмотра DVI-файлов [7]. Пока исключением является представление формул с помощью языка MathML, хотя именно этот способ является инновационным [8].
Отметим также, что обработка элементов математической нотации находится в фокусе многочисленных систем поиска по формулам, которые используют их специальное формализованное представление на языках OpenMath (http://www.openmath.org/standard) и MathML. На базе этих форматов решается более сложная задача – интерпретация семантики формул на языке LaTeX, чему, в частности, посвящен проект Uniquation (http://uniquation.ru). Вопросы формализации логической структуры математического документа и структуры объектов математического знания как ключевых характеристик исходных текстов и идеи семантических сервисов, расширяющих поисковые возможности в математических электронных коллекциях, в настоящее время обсуждаются [9]. В работе [10] предложена модель семантического поиска математических документов в электронных коллекциях, рассмотрены формат семантической разметки исходных документов, методы автоматического аннотирования документов и формального представления поисковых запросов на основе онтологий, классификации и формальной интерпретации поисковых запросов с учетом семантики исходных текстов.
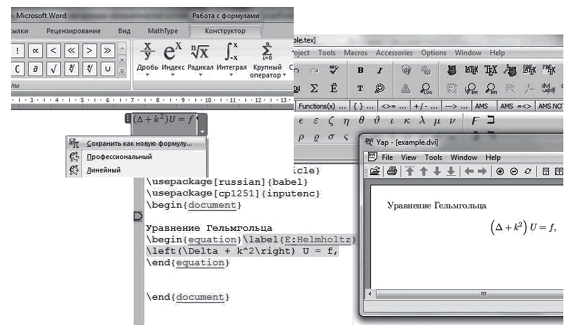
Рис. 2. Создание одной и той же формулы в MS Office + MS Equation и MikTEX + WinEdt
Систем подготовки математических текстов немного, в них используют либо редактор MS Word, дополненный пакетом MathType (или редактором формул MS Equation, входящим в MS Office), либо какую-либо систему, основанную на TEX-нотации (например, MikTEX) (рис. 2). Эта нотация принята ведущими издательствами физико-математической литературы, в частности Американским математическим обществом (www.ams.org) и российскими академическими журналами и издательствами. Крупнейший научный архив статей arXiv.org преимущественно содержит статьи в TEX-формате (а также файлы в форматах ps и pdf, скомпилированные из TEX-файлов статей).
Теговая система TEX-документа позволяет придать ему структурную выразительность, недоступную другим системам нотации. Это особенно важно при создании процедур автоматической обработки математических документов электронной коллекции и использовании программ конвертации (в том числе в формат MathML). Нотация TEX обладает практически всеми необходимыми компонентами для создания семантической разметки, однако эта возможность используется лишь частично. Вместе с тем технологии Семантического веба, интенсивное развитие которых наблюдается в настоящее время, направлены в первую очередь на связывание данных, содержащихся в различных электронных хранилищах, и обеспечивают создание языков разметки, адаптированных к определенной предметной области. Это позволяет гибко настраивать структуру электронного хранилища для включения контента новых предметных областей, в частности, математического [8].
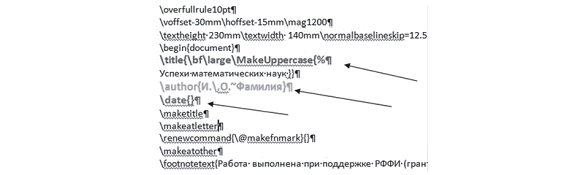
Рис. 3. Семантическая разметка информирует о содержании данных
Одной из рекомендаций Search Engine Optimization [10], направленных на повышение эффективности поиска, является организация ключевых слов и метаданных. Как известно, метаданные являются особым видом информационных ресурсов и содержат обобщенную информацию о структуре и содержании информационного источника, в том числе, данные об авторах публикации, ее названии и дате публикации, кодах предметной области и т.д. [11]. В электронных научных журналах комплексное использование метаданных, записанных по правилам Dublin Core и RDF, позволяет повысить эффективность поиска [8, 13]. Поэтому выделение метаданных можно использовать как технологию, позволяющую включить издания в систему глобального поиска.
Большая часть электронных математических коллекций состоит из неструктурированных текстов в различных форматах, как правило, pdf и TEX. Актуальной проблемой является создание методов автоматического извлечения из электронного источника идентифицирующих метаданных (в терминологии работы [12])), ключевых слов и библиографических ссылок [14, 15]. Ниже описаны подходы к решению этой проблемы, реализованные нами в электронных коллекциях математических изданий Казанского университета.
Экстракция метаданных электронных математических коллекций
Электронная коллекция математических изданий Казанского университета объединяет электронные варианты статей нескольких научных журналов и периодических сборников, а также электронные материалы научных конференций, изданные в трудах Математического центра им. Н.И. Лобачевского. Некоторая часть изданий представлена на портале Math-Net.ru (http://www.mathnet.ru/). Большой объем материалов этой коллекции исключает возможность ручного выделения метаданных, поэтому автоматизация этого процесса выполнена на основе исследования структуры самих электронных документов.
Особые требования к оформлению научных статей, предполагающие использование стилевых правил (обозначенных каждым научным журналом), были использованы как основа определения признаков, по которым выполнены автоматический разбор статей и выделение из их текста основных метаданных (например, названия, авторов). Теговая структура документа позволяет в автоматическом режиме однозначно выделить ряд текстовых элементов. Наличие структурных TEX-конструкций, таких как \author, \title и др., используемых в журнальных статьях, значительно упростило алгоритм разбора существенной части электронной коллекции. На рисунке 4 показаны фрагменты статей, имеющие структурное форматирование, принятое в журнале «Известия вузов. Математика» (структурные элементы выделены цветом).

Рис. 4. Выделение текстовых единиц с помощью теговой структуры документа
Автоматическое выделение библиографических данных из статей электронной коллекции сводится к поиску блока библиографии в документе и последующему разбору строк на библиографические составляющие. Окружение \begin{thebibliography}, используемое в большинстве журнальных статей, набранных в нотации TEX, позволяет однозначно вычленить библиографические объекты (рис. 5).

Рис. 5. Выделение библиографии; признаками служат положение и шрифтовое выделение
Следует отметить, что использование структурных конструкций системы TEX не является общепринятой практикой, и большие объемы электронных документов, в частности материалы научных конференций, не имеют структурной разметки, а блок библиографии также не всегда выделен структурно. Для этой части электронных документов в алгоритме автоматического разбора использованы особенности шрифтового оформления и порядок размещения текстовых элементов в документе.
Предварительно электронная коллекция математических документов была разделена на блоки, состоящие из электронных документов, имеющих одинаковое стилевое строение. Как правило, стилевое оформление математического научного журнала не изменяется достаточно долго (по крайней мере, в течение нескольких лет), что позволило вычленить всего несколько блоков документов. Далее с помощью процедуры стилевого приведения все электронные документы были приведены к единому стилю, после чего стала возможна автоматическая обработка всего массива электронных публикаций.
Помимо сервисов извлечения метаданных, информационная система управления электронными научными коллекциями должна включать сервисы контроля доступа к данным и метаданным, поиска в массивах разнородных метаданных, импорта метаданных из других информационных систем. Методы организации сервисов управления метаданными в распределенных информационных системах, интегрирующих разнородную научную информацию, рассмотрены в работе [16].
Заключение
Научные электронные издания и ресурсы растворены в потоке электронной информации, объем которого лавинообразно растет. Использование же стандартных сервисов и поисковых средств интернета применительно к научной электронной информации становится все менее эффективным. Кроме того, стандартная технология полнотекстового поиска не содержит инструментов для распознавания семантических отношений между объектами знания. Реализовать сервисы с расширенной поисковой функциональностью позволяют технологии Семантического веба, нацеленные, в частности, на разработку средств создания и поддержки больших интегрированных баз знаний на основе унифицированных семантических моделей.
Основные электронные математические коллекции размещены сегодня на порталах ведущих научных издательств, специализированных математических и естественно-научных порталах, в электронных библиотеках университетов и НИИ, электронных архивах, на навигационных сайтах и персональных страницах учёных. Представление математических текстов в интернете является сложной задачей, не имеющей в настоящее время стандартного и удовлетворяющего всех решения.
Электронные публикации по математике, помимо того, что они написаны на разных языках, имеют разнообразные формы представления и особенности использования математической нотации. Ведущими мировыми издательствами физико-математической литературы, в том числе российскими, принята TEX-нотация. Теговая система TEX-документа позволяет придать ему структурную выразительность, недоступную другим системам нотации. Это особенно важно при создании процедур автоматической обработки математических документов электронной коллекции и применении программ конвертации. Таким образом, нотация TEX обладает практически всеми необходимыми компонентами для создания семантической разметки, однако эта возможность используется лишь частично. По этим причинам поиск релевантных научных публикаций затруднен и обладает невысокой точностью.
Названные проблемы позволяют частично решить описанные выше способы совместного использования электронных коллекций с различающейся организацией, обусловленной особенностями использования математической нотации в электронных публикациях. Предложены модель интеграции математических электронных коллекций и комплекс методов, обеспечивающих автоматическое преобразование электронных публикаций с применением систем конвертации данных, объединения схем данных, а также стилевого приведения данных из разных коллекций в единое представление. Изложенные методы позволяют автоматически выделять из научных публикаций идентифицирующие метаданные и генерировать административные метаданные.
Работа выполнена при финансовой поддержке РФФИ (проекты 12-07-00667, 12-07-97018-р_поволжье).
Литература
1. Щур Л.Н. Роль инфокоммуникационных технологий в развитии процесса глобализации научных исследований // Информационное общество. 2012. № 5. С. 16–24.
2. Berners-Lee T. Semantic Web road map. URL: http://www.w3.org/DesignIssues/ Semantic.html; рус. перевод: http://gridclub.ru/library/publication.2007-04-23.2195467714/view
4. Berners-Lee T. Linked data – design issues. 2006. URL: http://www.w3.org/ DesignIssues/LinkedData.html
5. Kamareddine F., Wells J.B. Computerizing mathematical text with MathLang. Electr. Notes Theor. Comput. Sci. 2008. P. 5–30.
6. Kohlhase M. OMDoc – an open markup format for mathematical documents. Springer, 2006.
7. Шокин Ю.И., Федотов А.М., Богомяков П.А. Электронные журналы по математике (на примере электронной версии журнала «Вычислительные технологии»). URL: http://www-sbras.nsc.ru/win/elbib/journals/
8. Елизаров А.М., Липачев Е.К., Малахальцев М.А. Веб-технологии для математика: Основы MathML. Практическое руководство. М.: Физматлит, 2010. .
9. Жильцов Н.Г. Семантические сервисы для коллекций математических документов, представленных как Linked Data// Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды XII Всероссийская научн. конф. RCDL-2010, Казань, 13–17 октября 2010 г. С. 315-318. URL: http://rcdl.ru/doc/2010/315-318.pdf.
10. Биряльцев Е.В., Елизаров А.М., Жильцов Н.Г., Иванов В.В., Невзорова О.А., Соловьев В.Д. Модель семантического поиска в коллекциях математических документов на основе онтологий // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды XII Всероссийской научн. конф. RCDL-2010. Казань, 13–17 октября 2010 г. С. 296–300.
11. Enge E., Spencer S., Stricchiola J., Fishkin R. The Art of SEO. O’Reilly Media, 2012.
12. Когаловский М.Р. Метаданные, их свойства, функции, классификация и средства представления // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды XIV Всероссийской научн. конф. RCDL-2012 (Переславль-Залесский, 15–18 октября 2012 г.). Переславль-Залесский, 2012. С. 3–14. URL: http://rcdl.ru/doc/2012/paper3.pdf
13. Елизаров А.М., Липачев Е.К., Малахальцев М.А. Организация взаимодействия языков разметки в системе автоматизации электронных научных хранилищ: семантический подход // Научный сервис в сети Интернет: масштабируемость, параллельность, эффективность: Труды Всероссийской суперкомпьютерной конференции. 21–26 сентября 2009 г., г. Новороссийск. М.: Изд-во МГУ, 2009. С. 456–457.
14. Васильев А., Козлов Д., Самусев С., Шамина О. Извлечение метаинформации и библиографических ссылок из текстов русскоязычных научных статей // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды VIII Всероссийской научн. конф. RCDL-2007. Переславль-Залесский, 15–18 октября 2007 г. С. 175–184. URL: http://rcdl.ru/doc/2007/paper_24_v1.pdf.
15. Елизаров А.М., Зуев Д.С., Липачёв Е.К., Малахальцев М.А. Сервисы структурирования математического контента и интеграция электронных математических коллекций в научное информационное пространство // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: Труды XIV Всероссийской научн. конф. RCDL-2012. Переславль-Залесский, 15–18 октября 2012 г. С. 309–312. URL: http://rcdl.ru/doc/2012/paper47.pdf. URL: http://rcdl.ru/doc/2012/presentation47.pdf.
16. Жижимов О.Л., Пестунов И.А., Федотов А.М. Структура сервисов управления метаданными для разнородных информационных систем // Электронные библиотеки. 2012. Вып. 6. URL: http://www.elbib.ru/index. phtml?page= elbib/rus/journal/2012/part6/ZPF.
__________________________________
Елизаров Александр Михайлович - доктор физ.-мат. наук, профессор, заслуженный деятель науки Республики Татарстан, заместитель директора Института математики и механики им. Н.И. Лобачевского Казанского федерального университета
Липачев Евгений Константинович - кандидат физ.-мат. наук, доцент Института математики и механики им. Н.И. Лобачевского Казанского федерального университета
Хохлов Юрий Евгеньевич - кандидат физ.-мат. наук, доцент, академик Российской инженерной академии, председатель Совета директоров Института развития информационного общества