О журнале
Рекомендации
Обеспечение активности содержания многоязычия текстовых документов: технология Ключи о текста
Крейнес М.Г.
Обеспечение активности содержания многоязычия текстовых документов: технология КЛЮЧИ ОТ ТЕКСТА
М.Г. Крейнес
Московский специализированный Центр новых информационных технологий на базе Московской медицинской академии им. И.М. Сеченова
М.Г. Крейнес
Московский специализированный Центр новых информационных технологий на базе Московской медицинской академии им. И.М. Сеченова
ВведениеСуществующие объемы текстовой (в том числе, гипертекстовой) информации в электронной форме делают абсолютно нереальным личное знакомство человека с каждым текстом. Это определяет исключительную актуальность разработки информационных технологий, практически не требующих участия специалиста на этапе поиска необходимой информации и ее смысловой классификации. Традиционные методы информационного поиска по ключевым словам часто не приводят к отбору интересных текстов и отсеву неинтересных. Причина этого кроется не только в сложности для человека формирования в виде небольшого по объему списка слов, адекватного его желаниям поискового образа. Недостаточно эффективно само использование в качестве критерия отбора информации просто наличие в ней определенных слов, включенных в поисковый образ. Проблематичен и альтернативный подход – априорная, не ориентированная на конкретного пользователя, смысловая индексация текстов, среди которых выполняется поиск. Реальный путь создания эффективных методов смыслового анализа и поиска информации состоит в том, чтобы сделать активными сами документы: научиться синтезировать, исходя из анализа текста, наборы ключевых слов и аннотации, адекватные тематике и содержанию текста с точки зрения конкретного пользователя.
На основании оригинальной двухуровневой модели понимания и интерпретации текстовой информации (знаковый, семиотический уровень и семантический уровень, требующий непременного участия человека для содержательной интерпретации текста) нами предложено применить для реализации рассмотренных целей принципиально новые алгоритмы вычислительного синтеза смыслового образа текста. Основной особенностью этих алгоритмов является то, что они не используют информацию о смысле и значении слов, в частности, нет нужды в смысловых тезаурусах. Предлагаемые алгоритмы в ходе формальной процедуры выделяют своеобразное «семиотико-семантическое поле» – множество слов, наиболее сильно связанных по смыслу в конкретном анализируемом тексте, на основании сопоставления анализируемого текста с представительной для предметной области совокупностью текстов.
В результате внедрения созданных нами методов в работу электронных библиотек и телекоммуникационных сетей реализуются, во-первых, информационная технология интеллектуального смыслового поиска в информационных ресурсах на естественных языках без обязательного предварительного индексирования, а, во-вторых, автоматическая смысловая индексация, классификация и аннотирование текстовой информации как средства анализа и создания информационных ресурсов для глобальных телекоммуникационных сетей.
Основными особенностями предлагаемого подхода являются полнота и точность смыслового поиска и классификации информации, а также возможность описания сферы интересов пользователя в виде примеров интересных ему текстов. В этом случае решается задача поиска текстов тематически и по содержанию близких к заданным пользователем образцам.
Предлагаемая информационная технология ориентирована на конечных пользователей и провайдеров информационных услуг в глобальных телекоммуникационных сетях. Внедрение нашей технологии во многом решит острейшую проблему поиска данных, необходимых специалисту для эффективной работы с конкретной задачей.
Предлагаемые информационные технологии смыслового поиска информации представляют значительный интерес для различных предметных областей. Действительно, развиваемые нами технологии смыслового поиска предметно независимы, поскольку не нуждаются в тезаурусах и других формах толковых словарей.
Сегодня технология КЛЮЧИ ОТ ТЕКСТА, позволяющая анализировать тексты на русском и английском языках, реализована для различных операционных сред и вычислительных платформ.
При использовании технологии КЛЮЧИ ОТ ТЕКСТА возможна реализация многоязычия: формулировка задания на поиск на одном языке, поиск в информационных ресурсах – на другом языке. Действительно, основная идея технологии – идентификация в анализируемом тексте множества слов, наиболее сильно связанных друг с другом по смыслу, позволяет обратиться к линейным компьютерным переводчикам для формирования поисковых запросов на языке, отличном от языка образца. Комбинаторика сочетаний слов в машинном переводе запроса может порождать огромное число запросов (десятки или сотни тысяч), из которых лишь немногие будут реально осмысленными. Проведенные нами эксперименты с политическими и научными текстами подтвердили гипотезу о том, что именно этим запросам будут соответствовать не пустые результаты поиска. Это также открывает перспективы использования нашей технологии в системах машинного перевода для адаптивного, к предметной области или к конкретному пользователю выбора, конкретных вариантов перевода при исходной вариативности возможностей.
В этой работе:
- рассматриваются основные структуры и шаги семантического анализа и поиска текстовой информации в рамках технологии КЛЮЧИ ОТ ТЕКСТА;
- приведен типичный пример результатов анализа и поиска текстовой информации с использованием технологии КЛЮЧИ ОТ ТЕКСТА;
- обсуждены вычислительные характеристики и архитектура нашей компьютерной технологии.
Основные структуры семантического анализа текста и этапы поиска текстовой информации в технологии
КЛЮЧИ ОТ ТЕКСТАБазой для нашей технологии являются алгоритмы построения для любого текста «смыслового» портрета – множества слов, семиотически наиболее сильно связанных между собой в конкретном анализируемом тексте. Слово «смыслового» заключено в кавычки не случайно. Хотя при анализе и интерпретации человеком получаемых в результате вычислений списков слов очевидна их осмысленность и связь с тематикой, содержанием и смыслом исследуемого текста, никакой семантической информации и знаний о грамматике языка в ходе вычислений не требуется. Для выявления семиотически связанных слов применяется предложенная автором данной работы оригинальная метрика, использующая в качестве исходной информации только данные о комбинаторной статистике словоупотребления в анализируемом тексте и в некоторой совокупности текстов, представительной для языка, на котором написан анализируемый текст. Выбор такой референтной совокупности текстов равносилен формулировке позиций, с которых человек хочет воспринимать конкретный текст. Такой выбор можно ограничить текстами определенной группы носителей языка, например, профессиональной или политической. Задание референтной совокупности можно трактовать как неявное задание варианта (подмножества) языка, адекватного воспринимающему текст субъекту.
Таким образом, построение смыслового портрета основано на двух принципиальных гипотезах.
1. Семиотические характеристики (семиотические связи слов в тексте) являются определяющими для семантики текста.
2. Для понимания смысла конкретного текста необходимо определить совокупность текстов, в контексте которых следует воспринимать конкретный текст.
По существу, это практически фольклорные аксиомы в среде лингвистов, филологов и психологов. Достаточно вспомнить две классических формулировки:
- человек – это стиль,
- человек – это текст.
Справедливость сформулированных гипотез подтверждается высокой эффективностью вычислительного анализа текстов в технологии КЛЮЧИ ОТ ТЕКСТА.
Наша технология предполагает также, что следует идентифицировать различные словоформы каждого слова (например, одного существительного в различных падежах). Такая идентификация дает возможность абстрагироваться от конкретных грамматических форм слов при построении смысловых портретов текста. Для этого используются знания о языке, на котором написан текст. В реализованном нами варианте технологии такое распознавание (так называемая лемматизация) основано на специфическом морфологическом анализе, который позволяет с достаточно большой надежностью распознавать различные словоформы конкретных слов данного языка. На сегодня такой морфологический анализ реализован для русско- и англоязычных текстов.
Рассмотренные процедуры построения смыслового портрета текста решают задачу адаптивного к интересам конкретного носителя языка (профессиональной или политической группы, индивидуума, определенного автора, издания, группы изданий) вычислительного смыслового индексирования текстовой информации.
Результаты такого вычислительного индексирования интересны сами по себе, как средство автоматического создания вторичных информационных ресурсов – списков ключевых слов, адекватно, с точки зрения конкретного читателя, отображающих содержание и смысл текста. Одновременно смысловые портреты позволяют выделять в тексте наиболее важные для тематики и содержания всего текста фрагменты, что обеспечивает автоматическую генерацию рефератов. Наконец, появляется возможность вычислительной смысловой классификации текстов. Для этого предложена и используется специальная мера смысловой близости, основанная на вышеупомянутой метрике семиотической связанности слов в тексте.
Решение задачи вычислительного построения смыслового портрета текста позволило по-новому подойти и к задаче поиска текстовой информации. Речь идет не только о том, чтобы среди результатов поиска выбрать именно те, которые по содержанию и смыслу реально соответствуют запросу. Появилась возможность использовать в качестве запроса произвольный текст. Его смысловой образ, автоматически (в результате выбора референтной совокупности текстов) адаптированный к интересам читателя, в рамках технологии КЛЮЧИ ОТ ТЕКСТА трактуется как запрос. Результаты поиска по такому запросу, сгенерированному в ходе формальной вычислительной процедуры, анализируются для вычисления смыслового портрета каждого найденного текста. Затем выполняется сравнение смысловых портретов текста – образца и найденных текстов, анализ смысловой близости с запросом, по результатам анализа формируется окончательный корпус результатов. Сама процедура поиска может осуществляться средствами полнотекстовых баз данных (если тексты проиндексированы в таких базах) или собственными средствами нашей технологии, ориентированными на неиндексированные тексты. Итогом применения рассмотренной схемы являются не только высокоточные и полные результаты поиска, но и освобождение человека от необходимости решать очень сложную задачу описания своих интересов в виде короткого списка слов.
Результаты анализа и поиска текстовой информации с использованием технологии КЛЮЧИ ОТ ТЕКСТА (типичный пример в сравнении с MEDLINE)Для экспериментального исследования качества, точности и полноты смыслового индексирования и поиска информации с использованием технологии КЛЮЧИ ОТ ТЕКСТА было проведено сравнение результатов, получаемых с помощью нашей технологии и при применении одной из наиболее популярных профессиональных информационно-библиографических поисковых систем MEDLINE. Эта система, которая поддерживается Национальной медицинской библиотекой США, содержит библиографическую информацию о научных публикациях по медицинской тематике практически всего мира. В этой системе поддерживается следующая структура записи о каждом документе: название, авторы, достаточно полное библиографическое описание, реферат на английском языке (при условии наличия такого реферата в исходной публикации), набор ключевых слов для данной публикации, сформированный высоко профессиональным экспертом – сотрудником Библиотеки в рамках специального тезауруса. Подобная система необходима для экспериментов по объективной оценке нашей поисковой технологии, поскольку в иной ситуации при достаточно больших объемах анализируемой информации нет опорных точек для суждения о полноте поиска.
Эксперименты проводились следующим образом. Был выбран определенный фрагмент исходной базы данных (последние 5 лет и 114 журналов). Для разных образцов в качестве референтного проводился поиск в базе данных поисковыми средствами. В качестве запроса использовались те индексы, по которым образец был проиндексирован в базе. Было необходимо выбрать из всего набора индексов определенное его подмножество, поскольку попытка искать по полному списку индексов часто заканчивалась обнаружением только образца. Выбор указанного подмножества, как оказалось, не представлял существенных трудностей. При попытках использовать три или более индексных слова ситуация была та же, что с полным их набором. А отобрать, ориентируясь на текст реферата, два наиболее адекватных ключевых слова, не составляло труда для экспериментатора.
Для сравнения проводили поиск средствами нашей технологии в текстах, экспортированных из базы данных в текстовом формате. При этом сохранялись только заголовки и тексты рефератов (библиографические описания и индексные слова исключались). В качестве референтной совокупности были выбраны заголовки и тексты рефератов для всего массива данных (за исследованный период) того журнала, в котором был опубликован конкретный образец.
Приведем два примера.
Текст в базе данных MEDLINE:
Title: Alcohol-related injury death and alcohol availability in remote Alaska [see comments]
Authors: Landen MG; Beller M; Funk E; Propst M; Middaugh J; Moolenaar RL
Affiliation: Division of Field Epidemiology, Epidemiology Program Office, Centers for Disease Control and Prevention, Atlanta, Ga, USA.
Journal: JAMA ISSN: 0098-7484 Vol: 278 Iss: 21 Page: 1755-1758
Date: Dec 3 1997
Type: JOURNAL ARTICLE
Country of Publication: UNITED STATES Language: ENGLISH
Major MeSH: Alcohol Drinking [adverse effects]; Alcohol Drinking [epidemiology]; Alcoholic Beverages [supply & distribution]; Drug and Narcotic Control; Eskimos [statistics & numerical data]; Mortality [trends]; Wounds and Injuries [etiology]
Minor MeSH: Accidents [mortality]; Accidents [statistics & numerical data]; Adolescence; Adult; Alaska [epidemiology]; Alcohol Drinking [blood]; Alcoholic Beverages [utilization]; Alcoholic Intoxication [epidemiology]; Commerce; Comparative Study; Ethanol [blood]; Female; Human; Male; Wounds and Injuries [blood]; Wounds and Injuries [mortality]
Registry No: 64-17-5
Substances: Ethanol
Jrnl Group: Abridged Index Medicus; Cancer
Comments: Comment in: JAMA Dec 3 1997 Vol: 278 Iss: 21 Page: 1781-1782
Entry Month: 9802
Abstract: CONTEXT: Injury is a major public health problem in Alaska, and alcohol consumption and injury death are associated. OBJECTIVE: To determine the association between injury death, particularly alcohol-related injury death, and alcohol availability in remote Alaska. DESIGN, SETTING, AND PARTICIPANTS: Survey using death certificate data and medical examiner records to compare mortality rates for total injury and alcohol-related injury during 1990 through 1993 among Alaskans aged 15 years and older who had resided in remote villages of fewer than 1000 persons. MAIN OUTCOME MEASURES: Rate ratios of injury death among residents of wet villages (ie, those without a restrictive alcohol law) as compared with injury death among residents of dry villages (ie, those with laws that prohibited the sale and importation of alcohol). RESULTS: Of 302 injury deaths, blood alcohol concentrations (BACs) were available for 200 deaths (66.2%). Of these, 130 (65.0%) had a BAC greater than or equal to 17 mmol/L (> or =80 mg/dL) and were, therefore, classified as alcohol related. The total injury mortality rate was greater among Alaska Natives from wet villages (rate ratio [RR], 1.6; 95% confidence interval [CI], 1.3–2.1), whereas this difference was not present for nonnatives (RR, 1.1; 95% CI, 0.3–3.8). For Alaska Natives, the alcohol-related injury mortality rate was greater among residents of wet villages (RR, 2.7; 95% CI, 1.9–3.8) than among residents of dry villages. The strength of this association was greatest for deaths due to motor vehicle injury, homicide, and hypothermia. CONCLUSIONS: Although insufficient data existed to adjust for the effects of all potential confounders, residence in a wet village was associated with alcohol-related injury death among Alaska Native residents of remote Alaska villages. These findings indicate that measures limiting access to alcoholic beverages in this region may decrease alcohol-related injury deaths.
Copyright: This citation is derived from the National Library of Medicine’s MEDLINE
Здесь под рубриками Major MeSH и Minor MeSH представлены ключевые слова, по которым публикация проиндексирована в базе данных.
Title: Analyses of coronary graft patency after aprotinin use: results from the International Multicenter Aprotinin Graft Patency Experience (IMAGE) trial.
Authors: Alderman EL, Levy JH, Rich JB, Nili M, Vidne B, Schaff H, Uretzky G, Pettersson G, Thiis JJ, Hantler CB, Chaitman B, Nadel A.
Affiliation: Division of Cardiovascular Medicine, Stanford University Medical Center, Calif 94305, USA.
Journal: J Thorac Cardiovasc Surg, V 116, N 5, Page: 716-30
Date 1998
Major MeSH: Aprotinin [adverse effects], Coronary Artery Bypass, Graft Occlusion, Vascular [chemically induced], Hemostatics [adverse effects], Myocardial Infarction [chemically induced], K Adult, Aged, Anti-Inflammatory Agents, Non-Steroidal [administration & dosage] [adverse effects]
Minor MeSH: Aprotinin [administration & dosage], Aspirin [administration & dosage] [adverse effects], Blood Loss, Surgical [prevention & control], Cardiopulmonary Bypass, Graft Occlusion, Vascular [mortality], Hemostatics [administration & dosage], Heparin [blood], Middle Age, Myocardial Infarction [mortality], Risk Factors, Survival Rate, Veins [transplantation], Female, Human, Male, Support, Non-U.S. Gov’t
Abstract: OBJECTIVE: We examined the effects of aprotinin on graft patency, prevalence of myocardial infarction, and blood loss in patients undergoing primary coronary surgery with cardiopulmonary bypass. METHODS: Patients from 13 international sites were randomized to receive intraoperative aprotinin (n=436) or placebo (n=434). Graft angiography was obtained a mean of 10.8 days after the operation. Electrocardiograms, cardiac enzymes, and blood loss and replacement were evaluated. RESULTS: In 796 assessable patients, aprotinin reduced thoracic drainage volume by 43% (P <.0001) and requirement for red blood cell administration by 49% (P <.0001). Among 703 patients with assessable saphenous vein grafts, occlusions occurred in 15.4% of aprotinin-treated patients and 10.9% of patients receiving placebo (P=.03). After we had adjusted for risk factors associated with vein graft occlusion, the aprotinin versus placebo risk ratio decreased from 1.7 to 1.05 (90% confidence interval, 0.6 to 1.8). These factors included female gender, lack of prior aspirin therapy, small and poor distal vessel quality, and possibly use of aprotinin-treated blood as excised vein perfusate. At United States sites, patients had characteristics more favorable for graft patency, and occlusions occurred in 9.4% of the aprotinin group and 9.5% of the placebo group (P=.72). At Danish and Israeli sites, where patients had more adverse characteristics, occlusions occurred in 23.0% of aprotinin- and 12.4% of placebo-treated patients (P=.01). Aprotinin did not affect the occurrence of myocardial infarction (aprotinin: 2.9%; placebo: 3.8%) or mortality (aprotinin: 1.4%; placebo: 1.6%). CONCLUSIONS: In this study, the probability of early vein graft occlusion was increased by aprotinin, but this outcome was promoted by multiple risk factors for graft occlusion.
Copyright: This citation is derived from the National Library of Medicine’s MEDLINE
Технология КЛЮЧИ ОТ ТЕКСТА в результате вычислительной процедуры построила для первого из приведенных рефератов следующий смысловой портрет:
injury, alcohol, death, Native, mortality, greater, Alaska, village, remote, BAC (blood alcohol concentration), wet, law, dry, availability.
Для второго получили:
aprotinin, occlusion, patency, graft, International, ivein, occurred, sites, infarction, characteristics, loss, blood, treated, myocardial, patients, assessable.
Легко видеть хорошее совпадение индексов, вычисленных в результате формальной процедуры и построенных экспертами Национальной медицинской библиотеки США.
Сравнение результатов поиска также подтвердило весьма высокую эффективность нашей технологии. Например, для первого образца:
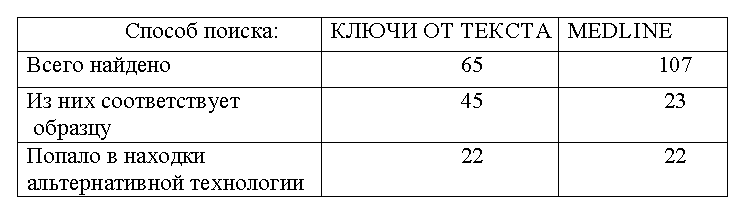
Приведенные результаты получены по итогам сравнения найденных текстов профессионалом-экспертом.
Вычислительные характеристики и архитектура компьютерной технологии смыслового поиска текстовой информации КЛЮЧИ ОТ ТЕКСТА
Принципиальной чертой технологии КЛЮЧИ ОТ ТЕКСТА является отсутствие необходимости в семантической информации для смыслового анализа текстовой информации. Видимо, это отражает глубинные свойства человеческой речи как семиотической системы. Оказалось, что если воспринимать текст как бытующий среди других текстов, его семиотические детерминанты могут быть выявлены в результате определенной вычислительной процедуры.
Безусловно, представляет интерес вычислительная трудоемкость технологии КЛЮЧИ ОТ ТЕКСТА. Вначале ориентировочные цифры: поиск по образцу с последующим смысловым анализом результатов в 10 Мбайт текстовой информации на современном персональном компьютере с процессором класса Pentium II требует примерно 10–30 секунд работы. Если не использовать для поиска механизмов баз данных, то время поиска растет примерно линейно при росте объема зоны поиска. Иначе ведет себя трудоемкость смыслового анализа текстов, если пытаться оптимизировать режим анализа информации. Такая оптимизация предполагает объединение анализируемых текстов в пакеты с последующим анализом пакета в целом. Выигрыш здесь достигается за счет того, что время, необходимое для создания компьютером структур, используемых для анализа текстовой информации, является выпуклой функцией от числа текстов. Причем, при малом числе текстов оно практически не зависит от их числа. В результате среднее время анализа одного текста при пакетном режиме анализа оказывается значительно меньше, чем время анализа одного отдельно взятого текста. Однако, при значительном росте числа текстов в пакете, трудоемкость растет значительно быстрее, чем линейно. Поэтому заложенная в основание технологии КЛЮЧИ ОТ ТЕКСТА ориентация на параллельные вычисления и работу в распределенных средах хранения данных способна реально обеспечить смысловой поиск и анализ текстовой информации в распределенных электронных библиотеках и информационных ресурсах глобальных телекоммуникационных сетей при применении мощных многопроцессорных сред и супер-ЭВМ.
1 Работа поддержана грантами РФФИ 98-01-00929 и 97-07-90131.
© Информационное общество, 2000, вып. 2, с. 43 - 47.