О журнале
Рекомендации
Распараллеливание эволюционных задач математических физики
Софронов И.Д., Софронова О.И.
_________________________________
И.Д. Софронов, О.И. Софронова
Статья подготовлена по материалам доклада на международной конференции по математическому моделированию. Рассмотрена эффективность использования мультипроцессоров с раздельной памятью для решения нестационарных задач вычислительной физики.
Класс задач
В качестве основного класса рассмотрим нестационарные многомерные задачи, описываемые уравнениями вида:
A![]() + B
+ B![]() + CU = D. (1)
+ CU = D. (1)
К этому классу принадлежат задачи адиабатической и высокотемпературной газовой динамики, газовой динамики с учетом сил прочности, детонации, кинетики различных реакций и т.д. [1].
Дискретизация задачи
Примем, что уравнение (1) определено в ρ-мерном гиперкубе Ω, в котором выбрана для простоты равномерная по всем направлениям сетка Ωh шагом n. Предположим, что вдоль границ Q поставлены корректным образом граничные
U|r = Ur (2)
и начальные условия
U (t=0) = Uo. (3)
В качестве дискретизации уравнений (1)-(3) выберем
ai![]() +
+ ![]() = c. (4)
= c. (4)
i = ![]() , R - некоторое число.
, R - некоторое число.
Дискретизация для двумерного случая
Решение поставленной задачи производится шагами по времени. Для t = 0 имеем начальные условия (3), по которым находим U1 = U(t = τ ∙ 1) и объявляем их новыми начальными данными и т.д.
В двумерном случае уравнения (4) можно переписать в более привычном виде разностного уравнения:
![]() + a
+ a![]() + b
+ b![]() + c
+ c![]() + d
+ d![]() + l
+ l![]() = f i =
= f i = ![]() (5)
(5)
или в векторной форме
![]() +
+ ![]() +
+ ![]() +
+ ![]() = D, i =
= D, i = ![]() (6)
(6)
где ![]() = (
= (![]() …
…![]() )T.
)T.
В случае (в) граничные условия принимают вид:
![]() +
+ ![]() =
= ![]() и
и ![]() +
+ ![]() =
= ![]() . (7)
. (7)
Применяемые методы решения
Для решения сформулированной задачи применяются различные методы, которые удобно разделить на четыре вида.
1. Явные методы: в уравнениях (4)-(6) параметр a полагается равным единице, и появляется возможность вычислить значения всех неизвестных функций для времени ![]() , где τ
, где τ ![]() h в случае гиперболичности некоторых уравнений и τ
h в случае гиперболичности некоторых уравнений и τ ![]() h2 - в случае их параболичности.
h2 - в случае их параболичности.
2. Неявные итерационные методы, когда на каждом шаге по времени итерациями решается исходное уравнение c a = 0.
3. Неявные методы с расщеплением по направлениям, когда решение
Pl-1/р-мерной задачи редуцируется к решению р(р - i)Nl~1/p одномерных
задач. При этом все одномерные задачи решаются методом прогонки.
4. Неявные методы с полной матричной прогонкой, которые позволяют найти точное решение (6)-(7).
Отметим, что первый и последний виды используемых решений дают точное решение многомерного разностного уравнения. Второй и третий виды дают лишь приближенное решение. При применении любого из перечисленных видов решений на машине с общей оперативной памятью принципиальных трудностей не возникает, если емкость оперативной памяти достаточна [2]. Есть только одно ограничивающее обстоятельство — это недостаточная производительность центральных процессоров. У многопроцессорных вычислительных систем с общей оперативной памятью невозможно наращивать без ограничения число процессоров, следовательно, нет возможности без ограничения наращивать ее арифметическую производительность. Последнее обстоятельство и вынуждало математиков последние десятилетия искать наиболее экономичные по арифметической работе алгоритмы. Появление вычислительных систем с разделенной памятью — мультикомпьютеров — сняло это ограничение, так как появилась возможность наращивания числа процессорных элементов (ПЭ) до нужного количества [8]. При этом, однако, возникла необходимость в обмене информацией между различными ПЭ. Чтобы подключить к решению одной задачи несколько ПЭ мультикомпьютера, необходимо разбить исходный гиперкуб Пл, содержащий N точек, на М меньших гиперкубов той же размерности, N
но содержащие по — точек. При этом, очевидно, все точки разобьются на М
два класса: внутренние и граничные. Под внутренними Точками будем понимать все точки, для вычисления нового значения решения в которых не требуется обращения за информацией в соседние гиперкубы. Под граничными точками, естественно, будем понимать все остальные точки. Из (4)-(6)следует, что граничные точки составляют слой точек, наиболее близко расположенных к поверхности гиперкубов. Опуская выкладки, приведем конечный результат. Из общего числа N точек при разбиении их на М более мелких гиперкубов
S - 2pAr1-1/pAf1/p (6)
становятся граничными. Для их вычисления необходимо из соседних гиперкубов переслать хотя бы одно число. Таким образом, при работе с муль-тикомпьютером мы вынуждены выполнить не только вычисления во всех точках, но и все необходимые пересылки информации. Последнее обстоятельство осуществляется системой коммутации. Очевидно время, необходимое для выполнения пересылок, зависит как от архитектуры системы коммутации (ОК), так и от пропускной способности линий связи. Используются различные архитектуры СК, рассмотрим некоторые наиболее популярные из них.
Оценка времени пересылок при использовании различных архитектур систем коммутации
Архитектура полного графа связей приведена на рис. 1.
Количество информации, которое надлежит переслать для вычисления одного шага по времени, определяется соотношением (8). Максимальная пропускная способность всех линий связи в рассматриваемом случа» пропорциональна м(м -l)-q>, тогда время, необходимое для пересылки всей информации будет
xrl-1/р
ф
На рис. 2 приведена двумерная матричная архитектура.
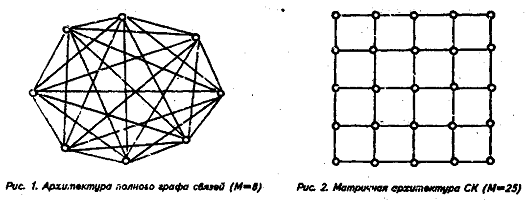
В рассматриваемой архитектуре только ближайшие ПЭ связаны между собой, связь между более отдаленными ПЭ осуществляется последователь -ностыо транзитных передач. Число тактов, за которое такая связь осуществится, определяется средним расстоянием между ПЭ, измеренным в количестве линий связи.
Для матричной размерности архтектуры среднее расстояние будет
t-M1/v.
Чтобы на одном шаге по времени переслать информацию объемом (8) на расстояние I при полной загрузке всех линий связи L о пропускной способностью ф, потребуется время Т, равное
у1-1/рМ1/р+1/.У-1
Тя " ;. (Ю)
При гиперкубической архитектуре системы коммутации (рис. 8) среднее .расстояние между ПЭ, измеренное в количестве линий связи, равно
Отсюда
Тя-" • (И)
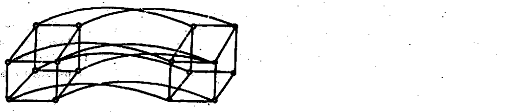
Рис. 3 Гиперкубическая архитектура (М=16)
Рис X Пищкц/бичФсхай архитектура (М— 1в)
Сравнение времени пересылок информации и времени выполнения арифметической работы
При счете одного шага по времени по явному методу или одной итерации по неявному надо выполнить арифметической работы в объеме
А-ей,
на что при полной загрузке всех ПЭ уйдет время, равное
Из (9) и (12) получаем:
Lfhgb;zk
ПЭ будет работать без простоев, если правая часть (18) больше единицы, т. е. если
. N>LM, (14)
ф
в противном .случае, время пересылок будет превосходить время выполнения арифметической работы.
Графически полученный результат изображен на рис. 4.
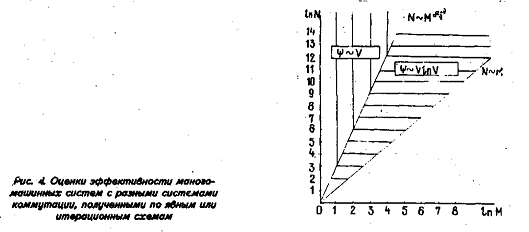
Во всех точках квадранта, расположенных левее прямой N - М ПЭ будут работать без простоев. Правее же этой прямой неизбежны простои. Заметим, что все наши опенки носят асимптотический характер и верны только для очень больших значений М и N.
Из (10) и (12) следует, что мультикомпыотер с матричной архитектурой будет работать без простоев в точках, расположенных левее прямой
p+v
N - М v , правее же этой прямой неизбежны простои ПЭ.
Из (11) и (12) заключаем, что мультикомпыотер с гиперкубической архитектурой будет работать без простоев ПЭ в точках, расположенных левее биссектрисы. Если мультикомпыотер работает без простоев, его производительность пропорциональна объему оборудования: у матричного мульти-компьютера это \у - V - М, у гиперкубического — <p~V\nV - MlnV. У
мультикомпьютера с полным графом связи ц/ — V2 — М2. На рис. 4—6 обозначены области, где каждый из этих мультикомпьютеров является самым эффективным.
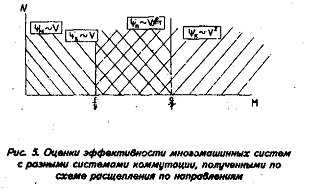
На рис. бив приведены такие же результаты, как и на рис. 4, только для метода с расщеплением по направлениям и для метода с полной матричной прогонкой.
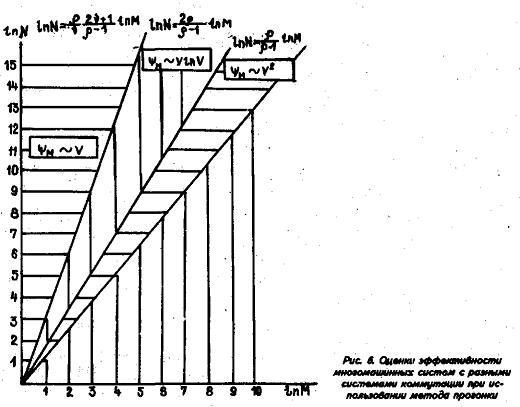
Заключение
В работе показано, что эффективность применения высокопараллельных систем зависит от архитектур системы коммутации и дискретизации исходной задачи. Найдены условия, при которых сохраняется линейный (по числу Процессоров) рост эффективности мультикомпькггеров, и условия, при которых невозможен этот линейный рост при увеличении числа процессорных элементов. Естественно, области линейного роста зависят от используемых алгоритмов. Показано, что у каждого алгоритма и каждой архитектуры системы коммутации на плоскости (М — число ПЭ и N — число точек в задаче) имеется область наиболее эффективного использования, которая приведена на рис. 4—6.
Литература
1. Рихтмайер Р., Мортон К. Разностные методы решения краевых задач. — М.: Мир, 1972.
2. Зарубежные ЭВМ в 1989—1990 гг./Под ред. Г. Г. Рябова. — М.: ИТМ и ВТ АН СССР, 1990.
3. Софронов И. Д., Софронова О. И. Эффективность многомашинных систем на эволюционных задачах математической физихи//ВАНТ. Сер. Мат. моделир. физ. проц., 1992. Вып. 8. С. 8—10.
Статья поступила в редакцию в декабре 1994 г.
Всероссийский научно-исследовательский институт экспериментальной физики (ВНИЙЭФ), г. Арзамас-16 Нижегородской обл.