О журнале
Рекомендации
Экспертная система "Cassandra" - программный пакет для моделирования деятельности человеческих сообществ
Дудихин В.В., Межуев И.Ю.
________________________
Дудихин В.В., Межуев И.Ю.
- Дается описание экспертной системы, позволяющей получить интересные практические результаты при анализе деятельности человеческих сообществ.
В результате работы получены теоретические методики и на их основе реализованы соответствующие программные продукты. Конкретными объектами для исследования были выбраны Верховный Совет и Съезд народных депутатов России. Все приводимые далее результаты справедливы в основном для этих сложных организационных систем. Разработанный авторами статьи программный пакет позволяет анализировать: расстановку политических сил и предсказывать результаты предстоящих голосований в этих выборных органах.
Естественно, это не первая попытка решения подобной задачи. Однако предлагаемая работа обладает существенной новизной подхода, что позволило получить интересные практические результаты. Например, применение метода для анализа деятельности Верховного Совета России дало возможность исследовать и моделировать различные варианты расстановки политических сил и с высокой точностью предсказывать результаты предстоящих поименных голосований в парламенте и на Съезде народных депутатов. Универсальность метода позволяет применять его не только в этом конкретном случае, но и для других объектов. Например для парламентов любых стран с демократической системой правления. Предлагаемый метод существенно дополняет имеющиеся методики обработки, данных. Его особенность — использование математической модели, способной к обучению и имеющей элементы искусственного интеллекта. Следует отметить, что эта работа была весьма своевременна в условиях России середины лета 1993 г., когда политические процессы вызывали необходимость в научном, оперативном и достоверном анализе и прогнозе.
Исследования расстановки политических сил в парламентах по результатам поименных голосований проводятся в разных странах в течение многих лет. Как правило, эти исследования состояли в классификации элементов исследуемых систем (депутатов парламентов) методами многомерного шкалирования. Например, классифицировались депутаты парламента по шкале консерватизм — либерализм, и строились соответствующие кривые на плоскости. Подобным подходом предпринимались попытки заменить сложную исследуемую систему на более простую ее модель, допускающую наглядную интерпретацию. Эти методы несомненно полезны, наглядны, убедительны и часто дают положительные результаты. Однако их применение имеет ряд ограничений. Сложная система может быть адекватно описана лишь в факторном пространстве достаточно высокой размерности (вероятно, десятки измерений). Но такое описание трудно визуализировать, а следовательно, теряются основные приемущества подхода, использующего приемы когнитивной графики. Ограничение размерности привычным для человека двух- или трехмерным пространством, естественно, снижает теоретически достижимую точность описания системы. Это вынуждает изобретать для осей пространства обобщающие характеристики, типа: либерализм, консерватизм, демократизм и т. п. Выводы о реальных процессах в системе выносятся на основании интерпретации косвенных величин и характеристик. Все это делает эти методы в большинстве случаев качественными и описательными.
Авторами статьи была предпринята попытка устранить некоторые из описанных ранее недостатков. В основе реализованного проекта лежат несколько основных идей:
преимущественно статистический подход при обработке входных данных; применение методов искусственного интеллекта; применение обучаемых моделей;
использование методов оптимизирующих параметры и структуру моделей.
Предполагалось, что в результате реализации должна быть получена математическая модель, способная предсказывать реакцию всей системы на входное воздействие, по известной реакции, любой, достаточно преставительной частичной выборки ее элементов, т. е., введя в модель возможное предстоящее голосование 15—20 известных исследователю депутатов, прогнозируются голосования 200 и более остальных членов парламента при решении этого вопроса в будущем.
В основе метода лежат следующие гипотезы:
позиции отдельных депутатов достаточно постоянны за исследуемые периоды времени;
возможно выделение стабильных пар депутатов, голосующих с большой степенью вероятности определенным образом (одинаково или противоположно);
количество таких пар депутатов достаточно велико, что позволяет сформировать базу знаний из правил IF — THEN — ELSE;
возможно построение эффективной машины логического вывода, вычисляющей голосования всех депутатов по предполагаемым голосованиям ограниченного их подмножества;
существует некоторая оптимизационная процедура, позволяющая корректировать внутренние параметры машины логического вывода и структуру базы знаний таким образом, чтобы точность прогноза была бы максимальной.
Для проверки выдвигаемых гипотез, на первой стадии реализации проекта, был разработан исследовательский прототип программного продукта на языке PROLOG. С его помощью была проведена проверка правильности основных теоретических положений на массиве прошедших голосований, когда находилась ошибка предсказания при сравнении прогноза с реальными голосованиями. В результате проделанной работы была получена методика, которую удобно представить в виде следующего алгоритма:
фильтрация входного массива поименных голосований. Так как преимущественно единогласные голосования не дают возможности выявить реальную расстановку политических сил, входные данные подвергаются фильтрации на основании разработанных критериев. Практика показала, что достаточно отобрать 30—40 последних, наиболее информативных голосований;
сравнение совпадения голосований депутатов каждого с каждым по "ЗА" во всех отобранных вопросах, и вычисление матрицы соответствующих коэффициентов (коэффициент равен 1 при полном совпадении голосований, 0 — при отсутствии совпадений);
формирование аналогичным образом матрицы коэффициентов совпадения по "НЕТ", "ВОЗДЕРЖАЛСЯ" и голосования противоположным образом;
формирование продукционных правил типа IF-THEN-ELSE-{K}, где К — коэффициент уверенности в диапазоне {0—1};
выбор индикаторной группы — некоторого количества депутатов, чье возможное голосование считается известным до проведения голосования;
выбор начальных порогов значимости для коэффициентов уверенности в правилах;
для всех отобранных голосований проводится логический вывод возможных результатов поименных голосований каждого депутата. Согласно алгоритму, разработанному авторами, для каждого депутата, не входящего в индикаторную группу, находятся вероятности голосования "ЗА", "ПРОТИВ", "ВОЗДЕРЖАЛСЯ". Окончательный исход прогноза зависит от того, какая из альтернатив набирает наибольшую величину предпочтения;
полученные для каждого депутата результаты прогноза сравниваются с реальными значениями голосований и вычисляются абсолютные и относительне ошибки прогноза;
если полученные величины абсолютных (и/или относительных) ошибок признаются приемлемыми, вводится возможное голосование членов индикаторной группы и логическим выводом вычисляется голосование остальных парламентариев. В противном случае производится оптимизация модели коррекцией коэффициентов;
если количество циклов оптимизации превосходило предельно допустимое значение (40—50), либо недостаточно количество и или качество исходных данных (поименных голосований), либо требования точности прогноза завышены. Необходимо изменение или порога фильтрации, или состава поименных голосований и т. п., затем повторение всех пунктов алгоритма, начиная с первого;
в случае удовлетворительной точности получаемого прогноза — окончание алгоритма.
В окончательном виде предлагаемый алгоритм был реализован в виде программного продукта — экспертной системы "Cassandra". Были созданы два варианта программного пакета "Cassandra" и "Cassandra Plus", первый — для Верховного Совета, второй — для Съезда народных депутатов. Программный пакет написан на языке программирования С++, а для построения интерфейса пользователя широко использовалась специализированная библиотека ZINC. В настоящее время в состав пакета входят модули FORECAST, COUNTER и TUNER.
Взаимодействие программных модулей экспертной системы "Cassandra" на различных этапах представлено на рис. 1, где 1 — генерация корреляционной матрицы; Г — выбор голосований для генерации матрицы; 2 — настройка коэффициентов (параметров) для машины логического вывода экспертной системы; 2 — выбор голосований для настройки коэффициентов; 3 — выбор индикаторной группы, для которой производится адаптация; 4 — выбор индикаторной группы для прогноза; 5 — прогноз.
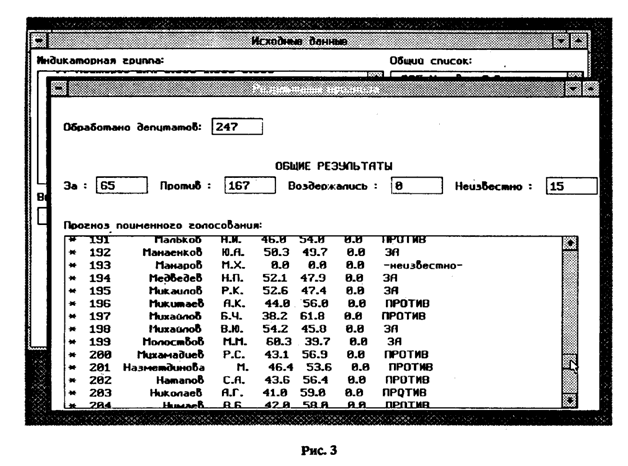
Модуль FORECAST предназначен непосредственно для осуществления прогноза и имеет развитый многооконный пользовательский интерфейс (рис. 2), позволяющий создавать индикаторные группы из общего списка депутатов и затем редактировать их, работать с файлами индикаторных групп, инициировать прогноз поименных голосований и наблюдать за его ходом (рис. 3). Окна, создаваемые программой, аналогичны окнам оболочки Windows и, как показывает опыт, требуется незначительное время для обучения пользователей работе с программой.
Программный модуль COUNTER предназначен для получения исходной матрицы корреляций между голосованиями каждой пары депутатов и коэффициентов, хранимых в файле конфигурации, управляющих работой машины логического вывода и продукционных правил IF-THEN-ELSE.
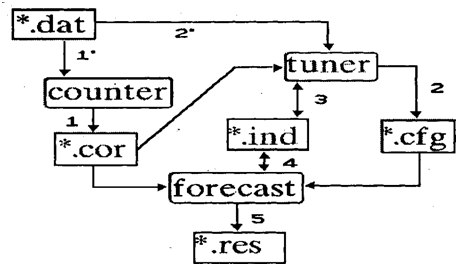
Рис. 1
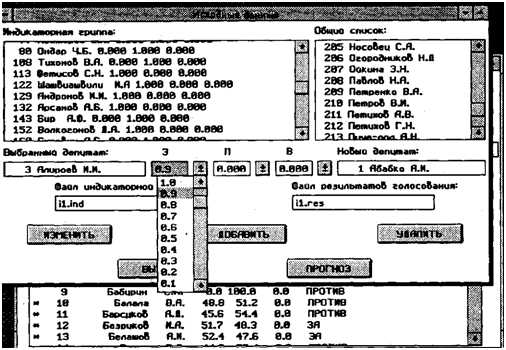
Рис. 2
Возможны два формата корреляционной матрицы. Первый формат (integer) содержит для каждой пары депутатов и для каждого возможного исхода голосования два числа. Этот формат удобно применять при настройке коэффициентов конфигурации. Однако процедура прогноза занимает больше времени при использовании этого формата. Второй формат (float) содержит вместо пары чисел их отношение в формате float (С++). Поскольку здесь хранятся уже непосредственно корреляционные коэффициенты, прогноз занимает значительно меньше времени. Для работы процедуры прогноза (программа FORECAST) необходимо задание ряда коэффициентов. Эти коэффициенты устанавливают различные пороги корреляций, которые учитываются программой прогноза. Коэффициенты выбираются таким образом, чтобы обеспечить наибольшее совпадение с имеющимися прошедшими голосованиями для выбранной индикаторной группы. У программы прогноза существует возможность в диалоговом режиме сформировать произвольную индикаторную группу, однако рекомендуется включать в нее тех депутатов, для которых производилась настройка коэффициентов.
Настройка коэффициентов осуществляется программой TUNER, входными данными для которой служат поименные голосования депутатов и матрица корреляций, созданная программой COUNTER. Данные о поименных голосованиях депутатов содержатся в базе данных формата DBase (файлы *.dat, см. рис. 1). Каждая запись этой базы содержит информацию об одном туре голосований. Необходим выбор из общего массива наиболее информативных голосований, отражающих расстановку политических сил (спорные вопросы). Программа TUNER запускает процедуру прогноза для каждого выбранного голосования, и полученный результат сравнивается с реальным, который также хранится в базе данных поименных голосований. Производится оптимизация коэффициентов для того, чтобы обеспечить результаты, как можно более близкие к реальным. Найденные коэффициенты сохраняются в файле (*.cfg, см. рис. 1) и используются программой прогноза FORECAST.
Экспертная система "Cassandra" эксплуатировалась в течение нескольких месяцев в Министерстве иностранных дел России. При ее работе ошибок предсказания общего исхода голосований зафиксировано не было. Результаты эксплуатации показали, что абсолютная ошибка предсказания поименного голосования в Верховном Совете не превышала 10—15, что соответствует относительной ошибке 5—7 %. Для Съезда народных депутатов величины ошибок составляли 50—70 голосов.
Особенностью предлагаемого подхода является инвариантность к численным, партийным и иным характеристикам рассматриваемых парламентов, так как он основан на обработке лишь статистических характеристик. Поэтому возможно его эффективное использование для прогноза голосований во всех странах с демократической системой правления. Кроме этого, весьма перспективными могут оказаться работы по дальнейшему развитию предлагаемых подходов в иных сферах человеческой деятельности (например, при проведении маркетинговых исследований, для прогноза функционирования бирж, деятельности команд политических деятелей и т. п.).
Научно-исследовательский центр
информатики МИД России
_________________________________
Дудихин В.В. - кандидат техн. наук
Межуев И.Ю.