О журнале
Рекомендации
Семантическая обработка информации больших баз данных
Артамонов Г.Г., Хомутов А.В.
___________________________
Артамонов Г.Г., Хомутов А.В.
Изложен формализм, позволяющий выполнять в информационных системах операции поиска аналогий, обобщенна и уточнения понятий, рассмотрения информационных элементов в заданном аспекте и установления логических соответствий между понятиями. Модель ориентирована на реализацию в рамках универсальных информационных систем с политематической базой данных.
Общая характеристика проблемы автоматизированной обработки смыслов
информации
Семантическая "мощь" автоматизированных .информационных систем определяется прежде всего свойствами той понятийной модели, которая лежит в основе формализованного представления смыслов информационных элементов средствами лингвистического* обеспечения системы. Наиболее распространенными в действующих "больших" информационных системах представления смыслов являются представления, построенные на базе классификационных иерархических моделей. Подобные схемы, как правило, порождают языки общения с системой без грамматики, что в свою очередь приводит к тому, что соответствие описаний информационных элементов базы данных (документов или фактов) описанию интересов пользователей устанавливается стратегией поиска [1].
В этом случае результаты решения задач представляются в виде подборок документов или фактов, извлеченных из базы данных и удовлетворяющих некоторой последовательности запросов, сформированных пользователем.
Такая модель естественным образом исключает возможность использования в полном объеме "семантической силы" информационного ресурса, накапливаемого в больших базах данных. Это происходит в первую очередь потому, что пользователь, работая с системой, лишен возможности провести какиелибо аналитические операции над информацией базы данных.
В настоящее время довольно интенсивно развивается направление, в рамках которого создаются экспертные системы, отличительной особенностью которых является включение в состав понятийной модели правил обработки информации, которыми пользователь может распоряжаться по своему усмотрению (в рамках заданного сценария) непосредственно в процессе решения задач. Но, как правило, каждая доведенная до промышленного внедрения экспертная система является узкотематической и содержит специфический набор правил, порожденный той или иной довольно ограниченной проблемикой областью. Так, например, в работе [2 ] приведен каталог экспертных систем, насчитывающий 176 наименований, каждая из которых помогает решать отдельные вопросы в области военного дела, геологии, инженерного дела, информатики, компьютерных систем, космической техники, математики, медицины, метрологии, промышленности, сельского хозяйства, управления процессами, физики, химии, электроники и юриспруденции. Анализ описаний этих систем заставляет сделать вывод о том, что их развитие идет экстенсивным путем как в области проблематики, для которой они создаются, так и в области инструментальных средств, с помощью которых они реализуются (в работе [2 ] приведен указатель инструментальных средств построения экспертных систем, насчитывающий 96 различных программных изделий).
"Интеллектуальное" развитие автоматизированных информационных систем, работающих с большими политематическими базами данных, на основе имеющегося опыта построения экспертных систем в настоящее время практически невозможно, поскольку одним из основных требований к подобного рода системам является независимость их программнотехнологических средств от свойств проблемной и предметной областей, в которых они работают.
Наиболее рациональным путем решения этой задачи с целью наиболее полного использования "семантической мощи" накопленного в системах информационного ресурса представляется переход от классификационных иерархических моделей к модели, предложенной в работе [1 ], тем более, что, как показано в работе [3 ], она позволяет, ко всему прочему, решить проблему языковой совместимости систем при объединении их в информационные сети.
Основным преимуществом этой модели по сравнению со всеми известными является то, что она позволяет учитывать в явном виде семантические свойства связей между понятиями, включенными в ее состав.
Рассматриваемая в настоящей работе модель относится к классу моделей, построенных на базе семантических сетей. Семантическим сетям посвящено довольно много публикаций, в которых рассматриваются различные аспекты моделирования с их помощью различных предметных областей. Здесь же мы предлагаем один из возможных способов формального описания семантических сетей, который, по нашему мнению, допускает хорошее смысловое истолкование в содержательных образах и понятиях.
Выше было указано, что основным ограничением понятийной модели, реализованной в какойлибо практически действующей информационной системе и определяющей правила взаимодействия с ней пользователя, является отсутствие в ее структуре механизмов, позволяющих автоматизировать процесс анализа информации, содержащейся в базе данныхили полученной в результате поиска. Для того чтобы найти путь к преодолению этого ограничения, необходимо прежде всего ответить на вопрос: какие операции должны автоматически выполняться системой, чтобы можно было сказать, что ей в какойто мере уже доступен семантический анализ информации?
Оставаясь на сугубо прагматических позициях, т. е. считая, что система только тогда принесет реальный эффект, когда с ее помощью решаются практические задачи, ответ на поставленный вопрос целесообразно искать, анализируя задачи, возникающие в повседневной практике.
Совершенно не претендуя на полноту полученных ниже результатов, ограничим поиск необходимых "интеллектуальных" операций рассмотрением следующих задач, решение которых весьма актуально для качественного развития современных информационных систем:
поиск семантических дублей при вводе новой информации в базу данных;
определение семантического соответствия результатов поиска содержанию породившего их запроса;
автореферирование текстов входных сообщений системы;
составление аналитических справок.
Актуальность задачи поиска семантических дублей при вводе информации в базу данных определяется тем, что в отсутствие средств для ее решения базы данных неоправданно "раздуваются", вследствие чего существенно усложняется технология их ведения.
Семантические дубли это по существу одна и та же информация, выраженная разными словами в двух или нескольких различных входных сообщениях. Очевидно, для поиска дублей необходимо уметь выделять семантическую структуру каждого сообщения и отождествлять их между собой.
Если несколько обобщить введенное понятие семантических дублей, то можно прийти к понятию смысловых аналогий. Действительно, в информационной практике зачастую встречаются сообщения, принадлежащие к различным предметным областям, построенные из различных понятий, но структура взаимосвязей сообщений может либо полностью, либо частично совпадать. В этом случае мы можем говорить о смысловой аналогии информации, заключенной в такого рода сообщениях. Поиск же таких аналогий тоже вполне актуальная и полезная задача.
Таким образом, для того чтобы в системе можно было осуществить поиск семантических дублей, необходимо в функциональном аппарате системы обеспечить выполнение операции "поиск аналогий".
Актуальность задачи определения семантического соответствия результатов поиска содержанию запроса обусловливается тем, что ее решение позволяет ввести в систему механизмы оценки качества работы и на их базе создать в системе обратные связи, регулирующие ее работу.
Поскольку результаты поиска по любому запросу представляют собой некоторую совокупность выходных сообщений (документов и фактов), то решение данной задачи распадается на два шага: первый это свертывание содержаний всех входящих в результаты поиска сообщений в единое сообщение и второй отождествление общего смысла этого сообщения с общим смыслом запроса.
Нетрудно видеть, что для реализации второго шага при решении данной задачи необходимы те же средства, что и при решении предыдущей задачи. Для реализации первого шага, т. е. для выполнения свертывания содержания некоторого множества сообщений, нужно уметь устранять дубли понятий, встречающиеся в различных сообщениях, и при необходимости заменять некоторые совокупности понятий на одно обобщающее их понятие, которое при этом должно встраиваться в семантическую структуру результирующего сообщения. Необходимость обобщения диктуется семантической структурой исходного запроса. Действительно, если в запрос входят понятия с большим объемом, чем понятия, образующие содержание отдельных сообщений; служащих результатами поиска, то сообщение, являющееся результатом решения данной задачи, должно содержать понятия, в которых сформулирован запрос.
Предпринятое рассмотрение этой задачи приводит нас к выводу о том, что система должна располагать средствами не только поиска аналогий, но и средствами обобщения содержания сообщений.
Актуальность задачи автореферирования текстов входных сообщений системы вполне очевидна. Реферирование текстов в настоящее время является весьма трудоемкой и рутинной процедурой, требующей больших затрат интеллектуального труда специалистов. К тому же, несмотря на существование соответствующих ГОСТов, добиться какойлибо унификации рефератов при условии, что их изготовляет множество самых разных людей, невозможно. А это порождает дополнительные трудности для автоматизированной их обработки.
С точки зрения методов решения автореферирование практически совпадает с предыдущей задачей и состоит в сжатии и обобщении текста исходного документа.
Составление аналитических справок это по существу целый класс 'задач, содержание каждой из которой определяется конкретным заданием. Но в то же время можно сделать несколько общих замечаний по поводу методов подготовки любой аналитической справки. Вопервых, необходим исходный материал для анализа, результаты которого должны быть представлены в справке. И этот исходный материал может быть получен в результате обработки запроса (серии запросов) к системе. Далее результаты поиска должны быть расклассифицированы в тех или иных аспектах, задаваемых в связи с целями анализа. В результате анализа должны быть сформулированы те или иные общие выводы, т. е. должно быть проведено обобщение конкретных сообщений, подлежащих анализу. Очевидно, что и исходный материал анализа, и выводы должны быть непро тиворечивы, а следовательно, должны быть установлены логические соответствия и выводов, и исходных фактов. Кроме того, результаты должны быть подкреплены фактическими данными, а отдельные положения, включаемые в справку, часто требуют более детального раскрытия. Сплошь и рядом при подготовке аналитических справок трудно найти требуемые решения непосредственно в той проблемной и предметной областях, в которых проводится анализ. В этих случаях прибегают к поиску и анализу аналогичных решений в смежных областях.
Изложенные замечания по методической подготовке аналитических справок позволяют сделать вывод о том, что, кроме уже отмеченных выше поиска аналогий и обобщения содержания сообщений, в системе необходимы средства, позволяющие рассматривать информацию в заданном аспекте, проводить уточнения (раскрытие) более общих понятий через понятия с меньшим объемом и устанавливать логические соответствия между понятиями анализируемых сообщений.
Таким образом, необходимый минимум "интеллектуальных" операций понятийной модели системы должен включать в себя следующие операции:
поиск аналогий;
обобщение исходных данных;
уточнение исходных данных;
рассмотрение информации в заданном аспекте;
определение логического соответствия элементов анализируемой информации.
Совершенно очевидно, что этот список далеко не полон, чтобы обеспечить возможность автоматизации решения всех мыслимых пользовательских задач. (Хотя в работе [4 ] утверждается, что процесс решения любой задачи представляет собой последовательность из поиска аналогий, обобщения и уточнения данных, выполняемых над различными фрагментами исходной информации.)
Не вызывает сомнения тот факт, что реализация перечисленных выше операций с помощью инструментальных средств системы, если и не решит проблемы создания универсальных баз знаний в целом, то позволит существенно повысить эффективность использования уже созданных политематических баз данных как документографических, так и объектографических.
В качестве вывода из материалов данного раздела можно сформулировать цель настоящей статьи разработка предложений по созданию понятийной модели автоматизированной информационной системы с большой политематической базой данных, позволяющей реализовать в системе механизмы выполнения перечисленных выше "интеллектуальных" операций.
Общая схема понятийной модели
В основе модели лежит понятие атомарной семантической сети, построенной из некоторой совокупности элементарных понятий, называемых "атомами", таким образом, что в прямой связи участвуют только два понятия и собственно связь между ними, называемая "контактом"![]() При этом каждое атомарное понятие в рамках модели полностью определяется совокупностью прямых связей, в которых оно участвует, а контанкт определяется множеством пар атомов, объединяемых этим контактом.
При этом каждое атомарное понятие в рамках модели полностью определяется совокупностью прямых связей, в которых оно участвует, а контанкт определяется множеством пар атомов, объединяемых этим контактом.
Обозначим атомарное понятие буквой![]()
Определение 1. Понятие![]() в модели считается атомарным, если любое другое атомарное понятие
в модели считается атомарным, если любое другое атомарное понятие![]() той же модели либо имеет с ним единственный контакт
той же модели либо имеет с ним единственный контакт![]() либо не имеет контакта.
либо не имеет контакта.
Прямую связь двух атомарных понятий обозначим тройкой![]()
В любой реально созданной понятийной модели в любой момент времени множества атомов![]() есть конечные множества, в состав
есть конечные множества, в состав
которых могут включаться новые элементы в процессе жизненного цикла информационной системы.
Множество связей в модели удобно задать тензором третьей валентности,
называемым тензором "смежности"![]() , координаты элементов которого
, координаты элементов которого
имеют вид![]() , а элементы определяются
, а элементы определяются
следующим образом:

Определение 2. Атомарной понятийной сетью![]() называется сеть, задаваемая тройкой A, R, Т, где А множество атомарных понятий, R множество контактов, Т тензор "смежности" атомарных понятий.
называется сеть, задаваемая тройкой A, R, Т, где А множество атомарных понятий, R множество контактов, Т тензор "смежности" атомарных понятий.
Геометрически атомарную понятийную сеть![]() удобно представить в качестве графа G
удобно представить в качестве графа G![]() с помеченными вершинами и нагруженными ребрами. Вершины этого
с помеченными вершинами и нагруженными ребрами. Вершины этого
графа помечаются именами атомарных понятий, а ребра нагружаются именами контактов.
Полным путем между вершинами![]() в графе, если он существует,
в графе, если он существует,
называется цепочка вида![]() такая, что каждая последующая
такая, что каждая последующая
пара вершин в этой цепочке является смежной и![]() Величина
Величина
/и называется длиной пути и обозначается m р ( п ) . Путь, для которого величина р (п) оказывается минимальной, является минимальным путем, а значение ![]() называется расстоянием между вершинами щ и щ. Для смежных
называется расстоянием между вершинами щ и щ. Для смежных
![]() не связаны друг с другом, то полагаем
не связаны друг с другом, то полагаем ![]() Естественно положить
Естественно положить![]()
Определение 3. Атомарная семантическая сеть![]() называется связанной, если для любой пары различных атомарных понятий
называется связанной, если для любой пары различных атомарных понятий![]() , т. е. существует хотя бы
, т. е. существует хотя бы
один путь, соединяющий вершины![]() в графе G, соответствующем этой сети.
в графе G, соответствующем этой сети.
Несвязанная понятийная сеть распадается на несколько связанных внутри себя кусков. Каждый такой кусок имеет свой набор атомарных понятий![]() причем
причем
![]() т. е. задают на множестве А структуру. (Это условие говорит о том, что при построении некоторой реальной сети в ее состав не должны включаться два различных атомарных понятия с одинаковыми именами.)
т. е. задают на множестве А структуру. (Это условие говорит о том, что при построении некоторой реальной сети в ее состав не должны включаться два различных атомарных понятия с одинаковыми именами.)
Для описания предметов, явлений, процессов, документов и пр. определенной выше атомарной семантической сети недостаточно, поскольку на практике для их описания зачастую используются сложные понятия, содержание которых раскрывается через некоторый набор атомарных понятий, объединенных в фрагмент сети теми или иными контактами. Для отражения в модели этой ситуации целесообразно пополнить ее понятием "блока"
Определение 4. Связанный фрагмент семантической сети, имеющий самостоятельное однозначное семантическое значение, называется понятийным блоком Ь. Каждый блок должен иметь свое имя.
Организация блоков будет рассмотрена несколько ниже, здесь же отметим только то, что не каждый фрагмент сети![]() может быть блоком, а вследствие двойственности определения понятий (дефиниция и конструктивное определение) понятия, выражаемые отдельными блоками, могут включаться в семантическую сеть в качестве атомов.
может быть блоком, а вследствие двойственности определения понятий (дефиниция и конструктивное определение) понятия, выражаемые отдельными блоками, могут включаться в семантическую сеть в качестве атомов.
Введенное понятие блока позволяет установить механизм интерпретации сложных понятий с помощью атомарной сети![]() , поэтому естественно пару
, поэтому естественно пару![]()
![]() множество блоков, определенных на
множество блоков, определенных на![]() ) назвать понятийной моделью информационной системы. Учитывая определение 3, понятийную модель М можно задать в следующем виде.
) назвать понятийной моделью информационной системы. Учитывая определение 3, понятийную модель М можно задать в следующем виде.
Определение 5. Понятийной моделью информационной системы называется четверка![]() , где А множество атомарных понятий, R множество
, где А множество атомарных понятий, R множество
контактов, Т тензор смежности понятий, В множество понятийных блоков.
Определение 5 задает понятийную модель информационной системы в целом и повторяет то, что уже сделано в работе [1 ]. Для получения строгого определения понятий аналогии, обобщения, уточнения, рассмотрения в заданном аспекте и логического соответствия понятий необходимо рассмотреть морфологию элементов атомарной сети.
Морфология элементов атомарной сети
Из сказанного выше легко видеть, что элементами атомарной сети являются атомы![]() , контакты
, контакты![]() и блоки
и блоки![]()
Каждый атом![]() обозначается ИМЕНЕМ, состоящим из пары (термин
обозначается ИМЕНЕМ, состоящим из пары (термин
естественного языка, код имени). Термин естественного языка служит для выражения соответствующего понятия в языковой системе пользователей, а код имени это внутрисистемное обозначение атомарного понятия.
Каждому атому![]() наряду с именем приписывается индекс типа понятия как некоторая семантическая характеристика, позволяющая расклассифицировать все
наряду с именем приписывается индекс типа понятия как некоторая семантическая характеристика, позволяющая расклассифицировать все
множество А по признаку объема понятий, выражаемых атомами, т. е.![]()
Из чисто практических соображений целесообразно задать следующее множество значений индекса типа
<«>:: {ОПБ, ОБ, НХ, ЗХ},
где ОП обобщенное понятие (например, физика, экономика, техника, медицина и т. д.);
ОБ объект (например, самолет, шприц, ЭВМ, завод и т. д.);
НХ наименование характеристики (например, вид документа, напряжение питания, цвет, цена, габариты и т. д.);
ЗХ значение характеристики (например, статья, 15 вольт, красный, 10 руб. и т. д.).
В реальной модели при необходимости множество < а > может быть расширено. Вообще это множество, как и множества атомов А, контактов R, блоков В, при реализации модели ведется экспертно в составе средств лингвистического обеспечения системы.
Следует отметить, что за каждым атомарным понятием, имеющим индекс < а > ![]() {ОП, ОБ}, стоит множество реальных объектов и явлений, составляющих объем соответствующего понятия. На этих множествах с помощью той или иной классификации может быть задана структура, которую мы будем называть "тематической областью" и которая в том или ином виде присутствует в каждой действующей информационной системе.
{ОП, ОБ}, стоит множество реальных объектов и явлений, составляющих объем соответствующего понятия. На этих множествах с помощью той или иной классификации может быть задана структура, которую мы будем называть "тематической областью" и которая в том или ином виде присутствует в каждой действующей информационной системе.
Индексы типа атомов также позволяют на множестве А задать структуру, т. е. разбить его на подмножества![]() такие, что
такие, что
Отсюда, в частности, следует, что реально могут быть найдены алгоритмы, преобразующие лексические средства действующих информационных систем, использующих другие понятийные модели, в лексические средства системы, построенной по предлагаемой модели.
Сопоставляя сказанное о способе описания атомарных понятий с определением
атомарной семантической сети, можно заключить, что каждый атом![]() обозначается именем, состоящим из термина естественного языка и кода имени, имеет смысловую характеристику в виде индекса атома, а содержание понятия этого атома полностью определяется его местом в семантической сети.
обозначается именем, состоящим из термина естественного языка и кода имени, имеет смысловую характеристику в виде индекса атома, а содержание понятия этого атома полностью определяется его местом в семантической сети.
По существу, каждый контакт![]() является также понятием, определяющим
является также понятием, определяющим
смысл прямой связи между любой парой атомов, объединяемых им. Поэтому при описании каждого контакта необходимо выделить две части: именующую часть, используемую для работы с контактом в составе сети, и смысловую часть, определяющую семантическое значение связей, установленных в сети с помощью этого контакта.
Именующая часть описания контактов так же, как и в случае описания атомов, выражается парой из термина естественного языка и внутреннего кода имени контакта.
Описание семантического значения каждого контакта удобно определить из следующих соображений.
Вопервых, в различных областях знаний используется различная терминология, являющаяся следствием исторического развития каждой из областей. Поэтому зачастую для выражения сходных сущностей используются разные термины. В частности, это касается и терминологии, используемой для выражения связей между понятиями. То есть довольно часты такие ситуации, когда глубинный смысл связи между парами понятий из разных областей знаний совпадает, а выражается это различными словами. Отсюда следует, что целесообразно в составе семантического значения контакта выделить так называемые узуальные свойства, характеризующие тематическую область, в которой имеет смысл данный контакт.
Определение 6. Узуальным значением![]() контакта
контакта![]() называется множество
называется множество
атомарных понятий, состоящее из атомов, имеющих < а >![]() ОП, и определяющее тематическую область, в которой данный контакт имеет смысл, т. е.
ОП, и определяющее тематическую область, в которой данный контакт имеет смысл, т. е.
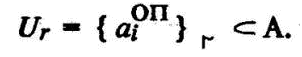
Каждое Ur формируется и ведется в составе лингвистического обеспечения системы экспертно.
Вовторых, для правильного представления смыслов в атомарной семантической сети, в особенности для представления смыслов сложных понятий (типа блоков), важны не только прямые связи, устанавливаемые непосредственно каждым контактом, но и косвенные связи атомов, отстоящих в сети друг от друга на расстоянии более единицы![]() . Для описания косвенных связей
. Для описания косвенных связей
выше были введены такие характеристики, как путь и расстояние, но они только фиксируют наличие той или иной косвенной связи между атомами и мало говорят о ее свойствах.
В то же время каждый контакт г в сети по определению связывает только два атома, а следовательно, его можно рассматривать как бинарное отношение. Известно, что любое бинарное отношение может быть охарактеризовано некоторым набором свойств, каждое из которых поддается строгому определению [5 ]. К таким свойствам бинарных отношений относятся рефлексивность, антирефлексивность, транзитивность, симметричность, анти и асимметричность, линейность, связность, равенство третьему, селективность и т. п.
Далее, если при определении каждого контакта в момент ввода его в семантическую сеть приписать ему соответствующий набор свойств бинарных отношений, то мы получим возможность охарактеризовать комбинаторные свойства сети в целом. Так, если контакт между парой атомов анти или асимметричен, то это, очевидно, означает, что соответствующая связь направленная, а если контакт симметричен, то связь нейтральна. Если же все контакты некоторого пути анти или асимметричны,то это означает, что между атомами, входящими в этот путь, существует нестрогий (строгий) порядок. Аналогично можно сделать соответствующие структурные выводы о некотором фрагменте сети, если его контакты обладают свойством транзитивности или какимлибо другим свойством из приведенного выше списка.
Определение 7. Комбинаторным значением К контакта ![]() называется
называется
подмножество бинарных отношений, записанное по принятым в данной системе правилам*, т. е.![]()
Опираясь на коммуникативные свойства контактов, можно разбить все множество R на два подмножества:
![]() подмножество ориентированных контактов;
подмножество ориентированных контактов;
![]() подмножество нейтральных контактов.
подмножество нейтральных контактов.
Это разбиение задается следующим определением.
Определение 8. Контакт ![]() называется ориентированным, если в его
называется ориентированным, если в его
коммуникативное значение![]() входит свойство анти или асимметрии бинарных отношений. Если в коммуникативное значение контакта входит свойство симметрии бинарного отношения, контакт является нейтральным.
входит свойство анти или асимметрии бинарных отношений. Если в коммуникативное значение контакта входит свойство симметрии бинарного отношения, контакт является нейтральным.
Нетрудно видеть, что на множестве R ориентированные и нейтральные контакты задают структуру, т. е.![]()
Втретьих, при правильной формулировке сложных понятий всегда используется внутренняя логика, присущая той области знаний, к которой относится как формулируемое, так и используемые понятия. Вследствие этого какиелибо используемые понятия могут находиться в причинноследственной связи, или быть несовместимыми при какихлибо условиях, или выражать, что одно является необходимым условием для другого и т. д. Поэтому при описании контактов в рамках рассматриваемой понятийной модели целесообразно указывать их логические свойства.
В общем случае всю совокупность L логических свойств всех контактов можно задать следующим перечислением:
дизъюнктивное ![]() свойство указывает на независимость связываемых
свойство указывает на независимость связываемых
контактом атомов;
конъюнктивное![]() свойство указывает, что одно понятие не может быть
свойство указывает, что одно понятие не может быть
использовано без другого;
импликативное![]() свойство указывает, что одно понятие является следствием другого;
свойство указывает, что одно понятие является следствием другого;
шеффертово ![]() свойство указывает на несовместимость понятий внутри
свойство указывает на несовместимость понятий внутри
одного сложного понятия.
Формально каждое из этих свойств определяется таблицей истинности соответствующих логических операций.
Очевидно, при практической реализации описываемой модели множество L ведется экспертно и может в случае необходимости пополняться.
Определение 9. Логическое значение![]() контакта
контакта ![]() называется элемент
называется элемент
множества L, приписанный контакту при определении его как элемента семантической сети![]()
Таким образом, совокупное![]() семантическое значение контакта задается тройкой
семантическое значение контакта задается тройкой
*Правила записи комбинаторных значений контактов должны выбираться так, чтобы обеспечивалась формальная сопоставимость этих значений друг с другом.
где Ur узуальное значение (определение 6);
![]() комбинаторное значение (определение 7); Lr логическое значение (определение 9).
комбинаторное значение (определение 7); Lr логическое значение (определение 9).
Очевидно, между комбинаторными и логическим значениями каждого контакта существует корреляция. Так, если контакт с логической точки зрения импликативный, то он не может быть симметричным в комбинаторном отношении. Но это вопрос более детального изучения свойств рассматриваемой модели, и ответ на него не сказывается на достижении цели, поставленной в этой работе.
Прежде чем рассмотреть морфологию блоков понятийной модели М, отметим,
что тензору связи Т можно однозначно сопоставить множество![]() связок вида
связок вида
![]() коды имен соответствующих атомов,
коды имен соответствующих атомов,![]() код имени контакта, а сама связка представляет собой неделимый
код имени контакта, а сама связка представляет собой неделимый
элемент сети. Если контакт, принадлежащий![]() , ориентированный, то и сама связка является ориентированной, причем началом связки служит левый атом, а концом правый.
, ориентированный, то и сама связка является ориентированной, причем началом связки служит левый атом, а концом правый.
Две связки ![]() и
и![]() называются сцепленными, если код имени одного атома первой связки совпадает с кодом имени одного атома другой связки. В этом случае
называются сцепленными, если код имени одного атома первой связки совпадает с кодом имени одного атома другой связки. В этом случае
будем говорить, что эти связки образуют сцепку![]()
Опираясь на введенные понятия связки и сцепки, можем переопределить на конструктивном уровне понятия блока.
Определение 10. Блоком![]() понятийной сети
понятийной сети![]() называется множество связок
называется множество связок
![]() , такое, что для любой связки
, такое, что для любой связки![]() найдется хотя бы одна несовпадающая и
найдется хотя бы одна несовпадающая и
сцепленная с ней связка ![]() . При этом все множество связок имеет
. При этом все множество связок имеет
самостоятельное смысловое значение.
Нетрудно показать, что определения блоков 4 и 10 эквивалентны.
Каждый блок bs можно охарактеризовать следующими количественными параметрами:
количество атомов блока, которое вычисляется по числу неповторяющихся кодов имен атомов во всех связках данного блока, это атомарная мощность блока,
обозначаемая![]() ;
;
количество неповторяющихся контактов блока это контактная мощность блока
![]()
количество связок блока это связность блока, обозначаемая![]() ,
,
структурный индекс блока ![]() .
.
Используя эти параметры, можно сказать, что: атом это блок с![]() ,
,![]()
связка это блок с![]() ,
,![]() ;
;
сцепка это блок с![]() ,
, ![]() ;
;
контакт это блок с![]() ,
,![]() не определен.
не определен.
Мы здесь рассмотрели формальную сторону построения блоков. Вопросы, связанные с их семантическими аспектами, требуют специального изучения и являются предметом специального исследования.
Представление информации с помощью понятийной модели
Реализация описанной выше понятийной модели в рамках какойлибо информационной системы представляет собой парадигматическое описание той предметной области, в которой работает информационная система. Это действительно так, поскольку все элементы модели (множество атомов А, множество контактов R, тензор смежности Т и множество блоков В) формируются в составе лингвистического обеспечения системы в процессе обработки документов и фактов из входного потока и концентрируют в себе обобщенные сведения о предметной области.
Результат построения понятийной модели в каждой системе является, скорее, квазипарадигматическим представлением предметной области, так как несет на себе отпечаток условий работы самой системы, но по отношению к тому разнообразию сведений о предметной'' области, которое содержит входной информационный поток, он оможет считаться парадигматическим. Поскольку при реализации модели от условий работы системы полностью абстрагироваться нельзя и основным фактором, влияющим на качество реализации моделей, является далеко не формальная работа специалистов, ведущих построение ее элементов, то полезно в составе семантической сети выделить части, согласующиеся с интуитивным представлением об организации практически любой предметной области. С этой целью весь граф![]() атомарной семантической сети
атомарной семантической сети![]() удобно разделить на подграф классификации
удобно разделить на подграф классификации![]() , подграф объектов
, подграф объектов![]() и подграф свойств
и подграф свойств![]()
Подграф классификаций образует атомы, имеющие индекс типа обобщенных
понятий![]() , ориентированные контакты, т. е.
, ориентированные контакты, т. е.![]() , где
, где![]()
![]()
Подграф объектов образуют атомы с индексом типа объектов ![]() , а
, а
контакты могут быть любые, т. е.![]() , где
, где![]()
Подграф свойств образуют атомы с индексом типа понятий или наименования или![]() значения характеристик и ориентированные контакты, т. е.
значения характеристик и ориентированные контакты, т. е.![]() , где
, где
Подграф классификаций имеет полииерархическую структуру, "корнями" которой являются атомы, выражающие наиболее общие понятия для данной предметной области. "Листьями" же этого подграфа, т. е. узлами, из которых не исходит ни одна из его ветвей, служат узлы подграфа объектов. Собственно подграф объектов это неплоский граф самого общего вида, а каждый его узел является к тому же одним из корней полииерархического графа свойств.
Естественно, основное назначение описанной выше модели состоит в представлении смыслов документов и фактов, вводимых в базу данных информационной системы и в совокупности представляющих собой синтагматическое описание предметной области последней. Решение любых пользовательских задач всегда связано с поиском и анализом элементов базы данных. Поэтому необходимо определить в рамках изучаемой модели такие элементы базы данных, как документ и факт. С этой целью переопределим понятия неявного или явного объекта, факта и документа, используемые в ряде действующих автоматизированных систем [6 ], для структурного представления информации в терминах данной понятийной модели.
Определение 11. Неявный объект это блок, представляющий собой конструктивное описание некоторого класса объектов и имеющий структуру иерархического графа, корнями которого являются атомы типов "объект" (т. е.
![]() и "наименование характеристики"
и "наименование характеристики"![]() .
.
Неявные объекты есть предметы лингвистического обеспечения системы. Определение 12. Явный объект это блок, образованный из какоголибо неявного объекта, пополненный атомами типа "значение характеристики" (т.е..
![]() и собственным именем описываемого объекта, называемым "маркой".
и собственным именем описываемого объекта, называемым "маркой".
Поскольку изза свойств входного информационного потока в какойлибо заданный момент времени составить полного образа явного объекта практически невозможно, то в базе данных системы, как правило, явные объекты представляются в виде совокупности фрагментов соответствующих блоков, принадлежность которых одному явному объекту устанавливается парой (атом с ![]() , марка). Каждый такой фрагмент называется "фактом". Факты, а следовательно и явные объекты, являются предметами базы данных.
, марка). Каждый такой фрагмент называется "фактом". Факты, а следовательно и явные объекты, являются предметами базы данных.
Весьма важным для практических целей является понятие неявного объекта специального вида "описания документа" и соответствующих ему фактов, называемых "библиографическим описанием".
Определение 13. Описание документа это неявный объект, корнем которого является атом с именем ДОКУМЕНТ, а остальные атомы отображают библиографические атрибуты научнотехнических, юридических и т. д. документов.
Определение 14. Библиографическое описание это факт, построенный на основе описания документа и содержащий библиографические сведения о какомлибо реальном документе.
Как правило, реальные документы, вводимые в базу данных, включают в себя множества взаимосвязанных фактов, в совокупности определяющих их содержание. Для того чтобы средствами модели отразить содержание документов, введем следующие вспомогательные понятия.
Два блока ![]() и
и![]() называются "смежными", если существуют связки
называются "смежными", если существуют связки![]() , такие, что один атом каждой из них принадлежит
, такие, что один атом каждой из них принадлежит![]() , а другой
, а другой ![]() . Количество связок, устанавливающих смежность блоков, будем называть "степенью смежности" и обозначим
. Количество связок, устанавливающих смежность блоков, будем называть "степенью смежности" и обозначим![]()
Совокупность попарно смежных блоков будем называть "предложением". Бели в предложении входящие в его состав блоки представлены их именами, то такое предложение называется "простым". Если же в предложении хотя бы один блок представлен множеством образующих его связок, такое предложение будет сложным.
Совокупность предложений, каждому из которых сопоставлено одно и то же библиографическое описание, есть текст, а пара, состоящая из текста и библиографического описания, это документ.
Аналогичным способом в рамках модели можно определить и другие крупные
информационные образования, такие как массив, проблемноориентированная
база данных и другие информационные объекты, с которыми имеют дело
автоматизированные информационные системы и которые являются объектами
информационных интересов пользователей.
По существу, эти информационные объекты являются операндами тех "смысловых" операций, определение которых в рамках развиваемой модели является целью настоящей работы.
Структурные соответствия в понятийной модели.
Самым простым сложным понятием в модели является блок, так как и предложения, и тексты, и массивы и т. д. строятся, как показано выше, из них. Поэтому рассмотрение структурных соответствий в модели ограничим здесь рассмотрением на уровне блоков.
Семантика каждого блока![]() в модели определяется тройкой вида
в модели определяется тройкой вида![]()
![]() , где
, где![]() множество атомов,
множество атомов,![]() множество контактов, а
множество контактов, а![]() тензор
тензор
сложности блока![]() . Очевидно, если для двух блоков
. Очевидно, если для двух блоков ![]() и
и![]() отдельные элементы, образующие соответственно
отдельные элементы, образующие соответственно![]() и
и![]() , какимлибо образом совпадают, то имеет смысл говорить о какихто семантических отношениях между понятиями, выражаемыми этими блоками.
, какимлибо образом совпадают, то имеет смысл говорить о какихто семантических отношениях между понятиями, выражаемыми этими блоками.
Первый случай, какой может быть, это когда часть атомов одного блока совпадает с частью атомов другого. Очевидно, смыслы соответствующих понятий в какомто отношении близки друг другу, т. е. эти понятия в чемто похожи, сходны. Поэтому целесообразно в модели определить сходство сложных понятий.
Определение 15. Два сложных понятия, выражаемые соответственно блоками![]() и
и![]() , называются соответственными, если выполняется условие
, называются соответственными, если выполняется условие![]() При этом величина
При этом величина![]() есть степень соответствия.
есть степень соответствия.
Интересными частными случаями соответствия являются случаи, когда:
1)![]() ;
;
2)![]()
Первый случай можно проинтерпретировать так, что понятие, выраженное блоком, может быть частью другого понятия, а второй что оба понятия описывают одну и ту же сущность с различных точек зрения.
АНАЛОГИЯ В ПОНЯТИЙНОЙ МОДЕЛИ
Часто на практике в различных областях знаний встречаются понятия, имеющие как бы похожую логическую организацию. Такое положение дел хорошо определяется понятием "аналогия" [7 ], которое, будучи использовано в процессе абстрактных рассуждений (что довольно часто имеет место при работе пользователя с информационной системой), достаточно продуктивно и, по существу, сводится к поиску структурных совпадений (поиска изоморфизма и гомоморфизма) понятий.
Для того чтобы в рамках модели задать строго понятие аналогии блоков, определим вначале структурный образ блока и назовем его "схемой блока".
Определение 16. Схемы блока![]() определяются следующим образом:
определяются следующим образом:
совокупность Ra всех контактов![]() , входящих в состав всех связок , элементом которых является атом
, входящих в состав всех связок , элементом которых является атом![]() , называется "кустом" атома
, называется "кустом" атома![]() в блоке
в блоке![]() ;
;![]()
множество контактов ![]() , входящих в состав
, входящих в состав![]() и упорядоченных вдоль некоторого пути блока
и упорядоченных вдоль некоторого пути блока![]() , называется "цепью" и обозначается
, называется "цепью" и обозначается![]()
пара, состоящая из множества всех кустов и множества всех цепей блока, есть полная схема этого блока![]() , гдеи;
, гдеи;
если в каждом кусте и каждой цепи![]() полной схемы
полной схемы![]() блока заменить каждый контакт на его логическое значение, то полученная в результате пара логическая схема блока;
блока заменить каждый контакт на его логическое значение, то полученная в результате пара логическая схема блока;![]()
если в каждом кусте и каждой цепи полной схемы блока заменить каждый контакт на его комбинаторное значение, то полученная в результате пара![]() комбинаторная схема блока.
комбинаторная схема блока.
Два блока ![]() и
и![]() с полными схемами
с полными схемами![]() и
и![]() называются
называются
подобными, если для их схем выполняются условия
![]()
Если аналогичное условие выполняется для логических (комбинаторных) схем блоков![]() и
и![]() , то эти блоки называются логически (структурно) подобными.
, то эти блоки называются логически (структурно) подобными.
Если для полных схем![]() и
и![]() блоков
блоков![]() и
и ![]() ; выполняются
; выполняются
условия![]() и
и ![]()
![]() .такие, что
.такие, что![]()
и ![]() то такие блоки называются "сходными", а
то такие блоки называются "сходными", а
![]() называется "подсхема сходства". Если аналогичные условия выполняются для логических (комбинаторных) схем блоков
называется "подсхема сходства". Если аналогичные условия выполняются для логических (комбинаторных) схем блоков ![]() и
и ![]() , то говорят, что блоки логически (структурно) сходны, а соответственно
, то говорят, что блоки логически (структурно) сходны, а соответственно ![]() называются
называются
подсхемами логического (структурного) сходства.
Теперь можно определить понятие аналогии для данной понятийной модели.
Определение 17. Два блока ![]() и
и![]() описывают (выражают) аналогичные
описывают (выражают) аналогичные
понятия, если они подобны или сходны. В этом случае говорят, что между соответствующими понятиями существует аналогия.
Используя различия в определении подобия и сходства схем блоков, удобно ввести следующую классификацию аналогий.
Аналогия двух смежных понятий называется "прямой", если соответствующие блоки подобны или сходны. Аналогия двух сложных понятий» называется "косвенной", если соответствующие блоки логически (структурно) подобны или сходна. Косвенная аналогия называется логической, если соответствующие блоки логически подобны или сходны. Косвенная аналогия называется структурной, если соответствующие блоки структурно подобны или сходны.
Прямая (косвенная) аналогия двух понятий называется полной, если соответствующие блоки просто (логически или структурно) подобны. Прямая полная аналогия называется просто аналогией. Прямая (косвенная) аналогия двух понятий называется "частичной", если соответствующие блоки просто (логически или структурно) сходны.
Части блоков, порожденные подсхемами сходства, называются "ядром аналогии". Количество контактов, входящих в ядро аналогии, называется "мощностью аналогии". Отношение мощности аналогии к общему числу контактов блока называется степенью аналогии.
Нетрудно показать, что все виды аналогий, заданные приведенной классификацией, обладают следующими свойствами бинарных отношений: рефлексивностью, симметричностью, транзитивностью, линейностью и равенству третьему. Другими словами, каждый вид аналогии есть бинарное отношение, заданное на множестве блоков понятийной модели, связность и понятийная мощность которых больше нулевой, т. е.![]()
ОБОБЩЕНИЕ СМЫСЛА ПРЕДЛОЖЕНИЙ
Определение 18. Простое предложение, образованное из сложного с помощью замены связок, содержащих атомы, на соответствующие связки, включающие имена блоков, называется "обобщением" или "обобщенным предложением". Имена блоков в обобщении объединяются в связки с помощью контактов, входящих в связки смежности исходного сложного предложения.
Обобщение смысла исходного сложного предложения выполняется с помощью покрытия всего множества образующих его связок. При этом обобщение считается "оптимальным", если покрытие осуществляется минимальным числом блоков.
УТОЧНЕНИЕ СМЫСЛА ПРЕДЛОЖЕНИЙ
Определение 19. Сложное предложение, образованное из другого предложения (простого или сложного) заменой связок, включающих в себя имя какоголибо входящего в исходное предложение блока, на множество связок, образующих этот блок, называется "уточненным".
Уточнение считается правильным (корректным), если в составе множества связок блока ест»» связки смежности, в каждой из которых и контакт, и второй атом принадлежат одной из связок, в которую входит имя заменяемого блока в исходном предложении. В противном случае считается, что либо семантическая сеть неполна, либо исходное предложение сформулировано неправильно.
ПРЕДСТАВЛЕНИЕ БЛОКОВ В ЗАДАННОМ АСПЕКТЕ
Определение 20, Если из множества связок, определяющих блок, удалены все связки, кроме тех, контакты которых отвечают заданному признаку, то говорят, что блок рассматривается в "аспекте", соответствующем данному признаку, и этот признак называется "аспектом".
В модели допускается три типа признаков, определяющих "простые" аспекты: тематические, логические, структурные. Соответственно каждая группа признаков порождает тематические, логические и структурные аспекты рассмотрения понятий, выражаемых блоками.
Любой тематический аспект задается логической формулой, операндами которой являются атомы, принадлежащие к подмножеству обобщенных понятий, т. е. имеющие индекс типа атома ![]() . Ограничения, налагаемые на
. Ограничения, налагаемые на
структуру логической формулы, определяются свойствами программного обеспечения, выбранного для реализации понятийной модели.
При представлении некоторого блока в заданном тематическом аспекте из его множества связок выбираются только те, узуальные значения контактов которых отвечают логической формуле, задающей аспект.
В смысловом отношении тематический аспект определяет понятие, описываемое блоком, в предметной области, заданной логической связью некоторых обобщенных понятий.
Любой логический аспект задается указанием одного логического свойства контактов (дизъюнктивного, конъюнктурного, импликативного или шеффертова). При представлении блока в заданном логическом аспекте из множества его связок оставляются связки, логические значения контактов которых совпадают с заданным аспектом. В смысловом отношении логические аспекты выявляют подструктуры блока, обладающие заданными логическими свойствами. Дизъюнкция логических аспектов тоже логический аспект.
Любой структурный аспект задается логической формулой, операндами которой являются свойства бинарных отношений. При представлении блока в структурном аспекте из множества его связок удаляются те из них, комбинаторное значение контактов которых не соответствует заданной логической формуле. В смысловом отношении структурные аспекты позволяют анализировать различные типы взаимосвязей внутри сложных понятий.
Композиция простых аспектов различных типов есть тоже аспект, который называется "комбинированным". Этот аспект можно построить перечислением простых аспектов. Представление блока в комбинированном аспекте осуществляется в последовательности, в которой перечислены простые аспекты при задании комбинированного. Поэтому два комбинированных аспекта, состоящие из одних и тех же простых аспектов, но записанных в разном порядке, есть два разных аспекта.
В различных аспектах можно рассматривать не только блоки, но и предложения, тексты и другие информационные образования.
ЛОГИЧЕСКИЕ СООТВЕТСТВИЯ В ПРЕДЛОЖЕНИЯХ
Если построить все множество путей, принадлежащих какомулибо предложению, выделить из них и вычислить значение функции истинности каждой из них на основании логических значений входящих в цепь контактов, то, очевидно, можно судить о логической совместимости атомов, образующих предложение. Это общее значение, а детально этот вопрос еще нуждается в проработке.
Практически в данном разделе дано формальное, определение всех выделенных выше смысловых операций, т. е. задача минимум настоящей статьи выполнена.
Выводы
1. Предложена понятийная модель информационной автоматизированной
системы, позволяющая формализовать выполнение таких семантических опера
ций, как поиск аналогий, обобщение и уточнение данных, рассмотрение
информации в заданном аспекте и установление логических соответствий между
понятиями исходного текста.
2. Предложенная модель служит достаточно хорошим основанием для создания
механизмов взаимопонимания различных информационных систем и инструмен
тальных средств администратора больших баз данных.
3. Целесообразно продолжить работу по уточнению предложенной модели и разработке способов ее реализации обеспечивающими средствами информационной автоматизированной системы.
4. Дальнейшую работу над моделью целесообразно продолжать в следующих направлениях:
провести экспериментальную проверку возможности алгоритмической реализации полученных семантических операций;
разработать методику формирования блоков и развития атомарной семантической сети с учетом уже созданных ее фрагментов;
разработать структуру файлов для представления семантической сети и ее элементов;
разработать алгоритмы для выполнения обобщения и уточнения данных, рассмотрения информации в заданном аспекте и выявления логического соответствия понятий в исходном тексте;
рассмотреть и предложить способы решения возможных пользовательских задач на базе предложенной модели.
Литература
1. А р т а м о н о в Г. Т. Основы прагматической информации. М., ВИМИ, 1985 (рукопись).
2. У о р т е н Д. Руководство по экспертным системам. М.: Мир, 1989.
3. Артамонов Г. Т., Антопольский А. Б. Проблемы разработки лингвистического обеспечения информационных сетей // НТИ. Сер. 2. М., ВИНИТИ, 1986, N 10.
4. П о й а Д. Математика и правдоподобные рассуждения. М.: Наука, Гл. ред. физ.мат. литры, 1975.
5. Бронштейн И. Н., С е м е н д я е в К. А. Справочник по математике для инженеров и учащихся втузов. М.: Наука, Гл. ред. физ.мат. литры, 1986.
6. К у з н е ц о в М. В., М о з д о р С. В., П о л т е в А. А., Хомутов А. В. Проектирование программнотехнологических комплексов интегрированных автоматизированных систем // Нормативные и методические материалы. Сер. Организация информационной деятельности. М., ВИМИ, 1989, вып. 4(23).
7. Философский энциклопедический словарь. М.: Сов. энциклопедия, 1983.
Статья поступила в редакцию 5 января 1991 г.
ВИМИ, МАИ им. Серго Орджоникидзе (Москва)
© Информационное общество, 1991, вып. 2, с. 41-55.